15 正则表达式
15.1 引言
正则表达式是一种描述字符串模式的简洁且常用的语言。简称为 regex 或 regexp。
本章要用到的包如下:
library(tidyverse)
library(babynames) #包含婴儿名字数据要用到以下三个 R 自带的字符串:
fruit:80 种水果;words:980 个英文常见词;sentences:720 个简短英文句子。
15.2 基础模式
str_view() 是学习 regex 的利器。它可以可视化匹配内容,将匹配的部分用 < > 包裹并高亮。以下对常见字符进行逐个说明。
- 最简单的正则表达式是字母或数字,直接匹配对应字符,称为字面匹配(Literal Match):
str_view(fruit, "berry")某些符号(如 .、+、*、[ ]、? 等)具有特殊含义,称为元字符(metacharacters)。
.匹配任意单字符:
str_view(fruit, "a...e") # 匹配“a开头,后跟任意三个字符,e结尾”的词- 下面三个符号称为量词(Quantifiers),匹配指定字符若干次:
| 符号 | 含义 |
|---|---|
? |
匹配 0 或 1 次(可选) |
+ |
匹配 ≥1 次(至少一次) |
* |
匹配 ≥0 次(可选+可重复) |
# ab? 表示匹配一个a,后可加可不加一个b
str_view(c("a", "ab", "abb"), "ab?")
#> [1] │ <a>
#> [2] │ <ab>
#> [3] │ <ab>b
# ab+ 表示匹配一个a,后加至少一个b
str_view(c("a", "ab", "abb"), "ab+")
#> [2] │ <ab>
#> [3] │ <abb>
# ab* 表示匹配一个a,后加任意数目的b(可无b)
str_view(c("a", "ab", "abb"), "ab*")
#> [1] │ <a>
#> [2] │ <ab>
#> [3] │ <abb>[]称为字符类(Character Classes),指定匹配多个字符之一:
[abcd] # 匹配 a 或 b 或 c 或 d
[^abcd] # 匹配不含 a/b/c/d 字符示例:寻找中间是 x 且两边为元音的词:
str_view(words, "[aeiou]x[aeiou]")|称为操作符(Alternation),表示多个可选模式:
str_view(fruit, "apple|melon|nut")示例:匹配含有指定关键词的水果:
pine<apple>, rock <melon>, coco<nut>15.3 关键函数
在掌握正则基础之后,可结合函数进行实用数据处理。
- 检测匹配
str_detect() 函数返回逻辑向量,判断字符串中是否匹配某个正则模式。
str_detect(c("a", "b", "c"), "[aeiou]")
#> [1] TRUE FALSE FALSE常与 filter() 结合使用,示例:查找包含小写 “x” 的人名并按使用次数降序排列:
babynames |>
filter(str_detect(name, "x")) |>
count(name, wt = n, sort = TRUE)
#> # A tibble: 974 × 2
#> name n
#> <chr> <int>
#> 1 Alexander 665492
#> 2 Alexis 399551
#> 3 Alex 278705
#> 4 Alexandra 232223
#> 5 Max 148787
#> 6 Alexa 123032
#> # ℹ 968 more rows可以将 str_detect() 与 summarize() 结合使用,通过 sum() 或 mean() 来统计匹配情况:
sum(str_detect(x, pattern)):返回匹配该正则表达式的观测值总数(即有多少个元素匹配);mean(str_detect(x, pattern)):返回匹配比例,即匹配元素占所有元素的百分比。
例如,以下代码统计并可视化了每年中包含字母 “x” 的婴儿名字所占的比例:
babynames |>
group_by(year) |>
summarize(prop_x = mean(str_detect(name, "x"))) |>
ggplot(aes(year, prop_x)) +
geom_line()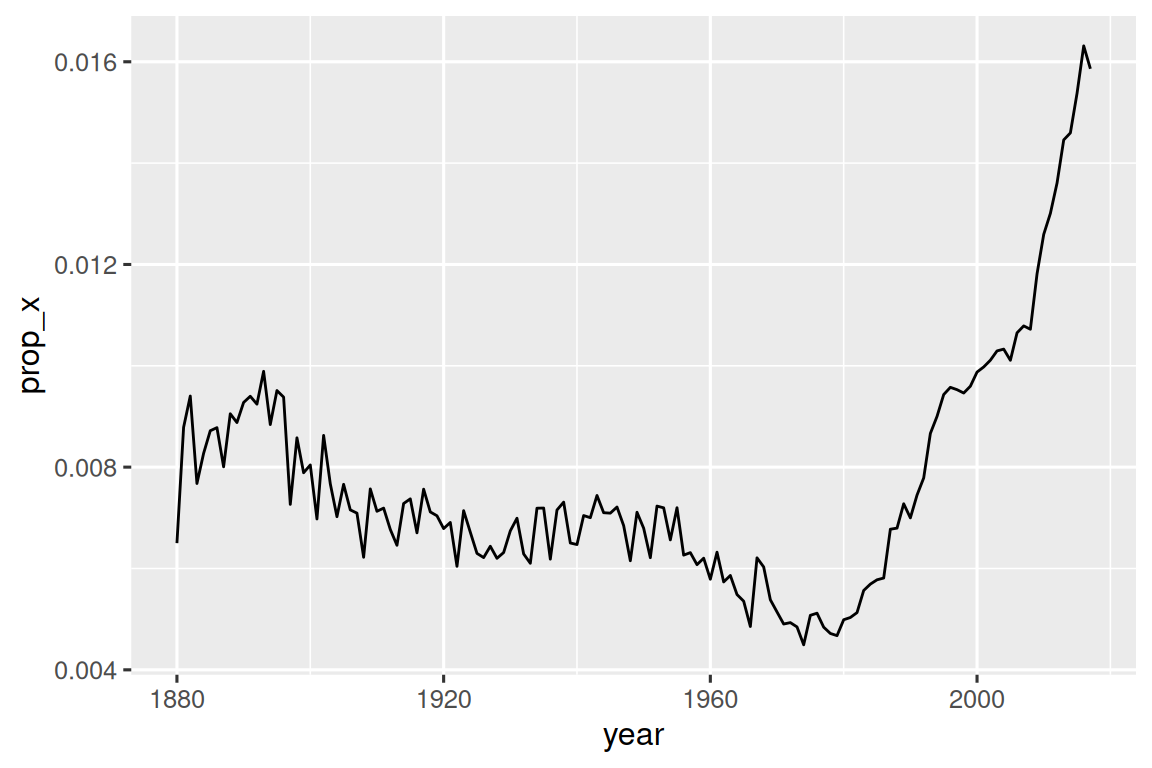
- 计数匹配
str_count() 返回每个字符串中匹配模式出现的次数:
x <- c("apple", "banana", "pear")
str_count(x, "p")
#> [1] 2 0 1需要注意,匹配的字段之间是不重叠计算的:
str_count("abababa", "aba")
#> [1] 2示例:统计人名中的元音和辅音数量
babynames |>
count(name) |>
mutate(
vowels = str_count(name, "[aeiou]"),
consonants = str_count(name, "[^aeiou]")
)上例结果偏小,因为正则默认区分大小写,可通过以下方式修正:
- 同时匹配大写字符:
"[aeiouAEIOU]" - 忽略大小写:
regex("[aeiou]", ignore_case = TRUE) - 预处理为小写:
str_to_lower(name)
- 替换值
使用 str_replace() 和 str_replace_all() 替换匹配的文本:
x <- c("apple", "pear", "banana")
str_replace_all(x, "[aeiou]", "-")
#> [1] "-ppl-" "p--r" "b-n-n-"删除匹配的内容可用 str_remove() / str_remove_all():
str_remove_all(x, "[aeiou]")
#> [1] "ppl" "pr" "bnn"这些函数常用于 mutate() 中进行数据清洗,通常需要多次重复处理以处理格式不一致的情况。
- 提取变量
使用 separate_wider_regex() 可将结构化的字符串拆成多列。
示例数据:
df <- tribble(
~str,
"<Sheryl>-F_34",
"<Kisha>-F_45",
"<Brandon>-N_33",
"<Sharon>-F_38",
"<Penny>-F_58",
"<Justin>-M_41",
"<Patricia>-F_84"
)提取其中的人名、性别和年龄:
df |>
separate_wider_regex(
str,
patterns = c(
"<",
name = "[A-Za-z]+",
">-",
gender = ".",
"_",
age = "[0-9]+"
)
)结果:
# A tibble: 7 × 3
name gender age
<chr> <chr> <chr>
1 Sheryl F 34
2 Kisha F 45
3 Brandon N 33
4 Sharon F 38
5 Penny F 58
6 Justin M 41
7 Patricia F 84使用
too_few = "debug"可以定位匹配失败的原因。
15.4 模式细节
- 转义(Escaping)
像字符串一样,正则表达式使用反斜杠 \ 进行转义。所以,为了匹配字面上的 .,需要使用正则表达式 \.。问题在于,我们是用字符串来表示正则表达式的,而字符串中 \ 同样是转义符。因此,要表示正则表达式 \.,需要写成字符串 "\\."。我将此总结为“嵌套式双重转义”。如下为例:
dot <- "\\."
str_view(dot)
#> [1] │ \.
str_view(c("abc", "a.c", "bef"), "a\\.c") # 匹配字面值 a.c
#> [2] │ <a.c>若要匹配字面上的 \ 本身,同样需要进行转义,即正则表达式为 \\。由于字符串中也需转义 \,所以最终写法是 "\\\\",即 4 个反斜杠代表一个字面上的 \:
x <- "a\\b"
str_view(x)
#> [1] │ a\b
str_view(x, "\\\\")
#> [1] │ a<\>b为避免多重嵌套转义的混乱,也可以使用原始字符串语法:
str_view(x, r"{\\}")
#> [1] │ a<\>b此外,对于诸如 .、$、|、*、+、 ?、 {、}、(、 ) 等特殊字符,也可使用字符类 [.]、[$] 等方式表示其字面值:
str_view(c("abc", "a.c", "a*c", "a c"), "a[.]c")
#> [2] │ <a.c>
str_view(c("abc", "a.c", "a*c", "a c"), ".[*]c")
#> [3] │ <a*c>- 锚点(Anchors)
默认情况下,正则表达式会匹配字符串中的任意部分。若希望仅匹配字符串开头或结尾,可使用锚点 ^(匹配开头)和 $(匹配结尾):
str_view(fruit, "^a") # 以a开头的字符串
#> [1] │ <a>pple
#> [2] │ <a>pricot
#> [3] │ <a>vocado
str_view(fruit, "a$") # 以a结尾的字符串
#> [4] │ banan<a>
#> [15] │ cherimoy<a>
#> ...虽然
$常被用在金额表示中放在前面,但在正则中,它表示结尾。
若希望整个字符串完全匹配某模式,同时使用 ^ 与 $即可:
str_view(fruit, "apple")
#> [1] │ <apple>
#> [62] │ pine<apple>
str_view(fruit, "^apple$")
#> [1] │ <apple>\b 可用于匹配单词边界(即单词的开头或结尾),常用于避免误匹配。例如搜索 sum() 时避免匹配 summary、rowsum 等:
x <- c("summary(x)", "summarize(df)", "rowsum(x)", "sum(x)")
str_view(x, "\\bsum\\b") # 注意转义
#> [4] │ <sum>(x)锚点本身是零宽度匹配:
str_view("abc", c("$", "^", "\\b"))
#> [1] │ abc<>
#> [2] │ <>abc
#> [3] │ <>abc<>- 字符类(Character Classes)
字符类用于匹配集合中的任一字符。可用 [] 来构造,例如 [abc] 匹配 a、b 或 c,[^abc] 匹配除这三者外的任意字符。在 [] 内部,除 ^ 外,还有两个具有特殊含义的字符:
-表示范围,如[a-z]表示小写字母,[0-9]表示数字;\用于转义特殊字符,如[\^\-\]]匹配^、-、]。
常见的字符类还有简写形式:
\d:数字,\D:非数字;\s:空白字符,\S:非空白;\w:字母或数字,\W:非字母或数字。
- 量词(Quantifiers)
量词控制某模式匹配的次数。 ?(0 或 1 次)、+(1 次或多次)、*(0 次或多次)。此外,{} 可指定更精确的匹配次数:
{n}:恰好匹配 n 次;{n,}:至少 n 次;{n,m}:匹配 n 到 m 次之间。
- 运算符优先级与括号
表达式 ab+ 是匹配 “a” 后接多个 “b”,还是多次匹配 “ab”?表达式 ^a|b$ 是匹配 “完整的 a 或 b”,还是 “以 a 开头或以 b 结尾”?
这取决于运算符优先级,就像算术中乘除优先加减一样。正则表达式中,量词优先级高,| 优先级低。因此:
ab+等价于a(b+);^a|b$等价于(^a)|(b$)。
为了避免歧义,建议使用括号明确结构。
- 分组与捕获(Grouping and Capturing)
括号不仅可以控制优先级,还能创建“捕获组”(capturing group),形如(...),以便在后续使用匹配子模式的结果。
\1 表示与第一个括号的内容相同,\2 表示第二个,以此类推:
str_view(fruit, "(..)\\1") # 找出两个连续字符重复的单词
#> banana, coconut, cucumber, etc.
str_view(words, "^(..).*\\1$") # 找出首尾两个字符一样的单词
#> church, decide, photograph, etc.可以在 str_replace() 中使用捕获组交换位置。例如将一句话第二个词和第三个词调个顺序:
sentences |>
str_replace("(\\w+) (\\w+) (\\w+)", "\\1 \\3 \\2") |>
str_view()
w+表示字母或数字类
若要提取每个组的匹配结果,使用 str_match():
str_match("the (\\w+) (\\w+)") 除了捕获组,还可使用非捕获组,形如 (?:...),只用于匹配,不保存匹配内容,不会出现在 \\1 里。
str_match(x, "gr(?:e|a)y")
#> "gray", "grey"15.5 模式控制
有一些设置可以用来调整正则表达式的细节,这在其他语言中通常被称为 flags(标志)。可以通过 regex() 函数将字符串包裹起来来使用这些设置。
最常用的标志有:
ignore_case = TRUE:忽略大小写
bananas <- c("banana", "Banana", "BANANA")
str_view(bananas, "banana")
#> 只匹配 "banana"
str_view(bananas, regex("banana", ignore_case = TRUE))
#> 同时匹配 banana、Banana 和 BANANAdotall = TRUE:让.匹配换行符(\n)
x <- "Line 1\nLine 2\nLine 3"
str_view(x, ".Line")
str_view(x, regex(".Line", dotall = TRUE))下面一行的代码将正则表达式
.Line改写为允许点号.匹配换行符,即让点号真正变成“匹配任意字符(包括换行)”。这样就能跨越行与行之间的\n,成功匹配\nL这种中间有换行的情况。
multiline = TRUE:让^和$匹配每一行的开头和结尾。
x <- "Line 1\nLine 2\nLine 3"
str_view(x, "^Line") # 默认只匹配第一行
str_view(x, regex("^Line", multiline = TRUE))
#> 匹配每一行的 Linecomments = TRUE:允许使用空格和注释来增强可读性
可以在正则表达式中添加空格和 # 注释来解释每一部分。这些空格默认会被忽略,如要匹配空格或 #,则需使用反斜杠转义。
phone <- regex(
r"(
\(? # 可选的左括号
(\d{3}) # 三位区号
[)\-]? # 可选的右括号或短横线
\ ? # 可选空格
(\d{3}) # 三位号码
[\ -]? # 可选空格或短横线
(\d{4}) # 四位号码
)",
comments = TRUE
)
str_extract(c("514-791-8141", "(123) 456 7890", "123456"), phone)
#> 提取出电话号码除了 regex() 函数包裹的标志设置,还可以通过 fixed() 函数来关闭正则表达式的规则,直接按字面意义匹配:
str_view(c("", "a", "."), fixed("."))
#> 只匹配真正的 “.” 字符也可以配合 ignore_case = TRUE 忽略大小写:
str_view("x X", fixed("X", ignore_case = TRUE))
#> 匹配 x 和 Xstr_view("i İ ı I", fixed("İ", ignore_case = TRUE))
#> 在默认