25 函数
25.1 引言
提升工作效率的最佳方式之一是编写函数。函数比复制粘贴更强大、更通用、更自动化。
具体而言,编写函数有以下优势:
- 可以为函数起一个专属名称,让代码更易读。
- 只需在一处更新代码,而无需修改多处。
- 可在不同项目中复用代码,从而长期提升生产力。
当复制粘贴某段代码超过两次,或同一代码有三份副本,就应该考虑将其改写为函数。
本章介绍三种实用的函数类型:
- 向量函数:输入一个或多个向量,返回一个向量。
- 数据框函数:输入一个数据框,返回一个数据框。
- 绘图函数:输入一个数据框,返回一个图形。
我们将整合tidyverse中的多种函数,并依旧使用老熟人nycflights13作为示例数据来测试这些函数。
library(tidyverse)
library(nycflights13)25.2 向量函数
首先介绍向量函数。向量函数接受一个或多个向量作为输入,并返回一个向量作为输出。
25.2.1 编写
编写函数的第一步是分析重复代码,找出哪些部分是固定的,哪些部分是变化的。
比如下面这个数据框相关代码:
df <- tibble(
a = rnorm(5),
b = rnorm(5),
c = rnorm(5),
d = rnorm(5),
)
df |> mutate(
a = (a - min(a, na.rm = TRUE)) /
(max(a, na.rm = TRUE) - min(a, na.rm = TRUE)),
b = (b - min(b, na.rm = TRUE)) /
(max(b, na.rm = TRUE) - min(b, na.rm = TRUE)),
c = (c - min(c, na.rm = TRUE)) /
(max(c, na.rm = TRUE) - min(c, na.rm = TRUE)),
d = (d - min(d, na.rm = TRUE)) /
(max(d, na.rm = TRUE) - min(d, na.rm = TRUE)),
)
#> # A tibble: 5 × 4
#> a b c d
#> <dbl> <dbl> <dbl> <dbl>
#> 1 0.339 0.387 0.291 0
#> 2 0.880 -0.613 0.611 0.557
#> 3 0 -0.0833 1 0.752
#> 4 0.795 -0.0822 0 1
#> 5 1 -0.0952 0.580 0.394显然 mutate()中的部分有多次重复,不妨将其单独提出,每一行代表一次重复:
(a - min(a, na.rm = TRUE)) / (max(a, na.rm = TRUE) - min(a, na.rm = TRUE))
(b - min(b, na.rm = TRUE)) / (max(b, na.rm = TRUE) - min(b, na.rm = TRUE))
(c - min(c, na.rm = TRUE)) / (max(c, na.rm = TRUE) - min(c, na.rm = TRUE))
(d - min(d, na.rm = TRUE)) / (max(d, na.rm = TRUE) - min(d, na.rm = TRUE)) 可以用一个占位符 █表示变化部分:
(█ - min(█, na.rm = TRUE)) / (max(█, na.rm = TRUE) - min(█, na.rm = TRUE))要将其转换为函数,需要三个关键组成部分:
- 函数名(name):此处使用
rescale01,表示将向量缩放至 [0, 1]。 - 参数(arguments):此处只需一个参数,命名为
x。 - 函数体(body):即重复代码的逻辑。
遵循以下模板:
name <- function(arguments) {
body
}对应本例:
rescale01 <- function(x) {
(x - min(x, na.rm = TRUE)) / (max(x, na.rm = TRUE) - min(x, na.rm = TRUE))
}可以用简单输入进行测试:
rescale01(c(-10, 0, 10)) # [1] 0.0 0.5 1.0
rescale01(c(1, 2, 3, NA, 5)) # [1] 0.00 0.25 0.50 NA 1.00随后重写 mutate() 调用:
df |> mutate(
a = rescale01(a),
b = rescale01(b),
c = rescale01(c),
d = rescale01(d),
)25.2.2 优化
注意到 rescale01() 中 min() 和 max() 被多次调用,可以用 range()进行简化:
rescale01 <- function(x) {
rng <- range(x, na.rm = TRUE)
(x - rng[1]) / (rng[2] - rng[1])
}
range()函数接收数值向量,输出最小值和最大值。
再用包含无穷值的向量检验函数:
x <- c(1:10, Inf)
rescale01(x) # 返回值含 NaN,不理想可以用 finite = TRUE 参数忽略无穷值:
rescale01 <- function(x) {
rng <- range(x, na.rm = TRUE, finite = TRUE)
(x - rng[1]) / (rng[2] - rng[1])
}25.2.3 变换函数(mutate functions)
现在我们已大致了解了函数的编写过程,下面通过介绍一些具有特定功能的函数进行深入说明。
变换函数是一类输入与输出的向量长度一致的函数,故而其结果适用于 mutate() 和 filter() 。
标准化 Z-score函数的结构如下,与刚刚编写的rescale01比较类似:
z_score <- function(x) {
(x - mean(x, na.rm = TRUE)) / sd(x, na.rm = TRUE)
}再如下面的字符向量操作,能够将首字母转为大写:
first_upper <- function(x) {
str_sub(x, 1, 1) <- str_to_upper(str_sub(x, 1, 1))
x
}
first_upper("hello") # "Hello"细节说明:
str_sub(x, 1, 1):提取每个字符串的第1个字符,1, 1表示从第1个字符开始,到第1个字符结束。
str_to_upper():将字符转为大写。最后的
x表示返回修改后的完整字符串向量。
25.2.4 汇总函数(summary functions)
接下来是汇总函数,一般用于 summarize(),能够返回一个单值。
下面是用逗号连接字符串的一个汇总函数:
commas <- function(x) {
str_flatten(x, collapse = ", ", last = " and ")
}
commas(c("cat", "dog", "pigeon")) # "cat, dog and pigeon"细节说明:
str_flatten():将字符向量合并为单个字符串。collapse = ", "表示普通元素间用逗号+空格分隔;last = " and "表示最后两个元素之间用 and 连接。
也可以输入多个向量,而输出仍是单值。例如下面用于计算 MAPE(平均绝对百分比误差)的函数:
mape <- function(actual, predicted) {
sum(abs((actual - predicted) / actual)) / length(actual)
}写函数时,以下 RStudio 快捷键非常方便:
- 查看函数定义:将输入光标置于函数名上,按 F2。
- 跳转到函数:按 Ctrl + . 可打开模糊搜索,可跳转到函数、文件或 Quarto 小节等位置。
25.3 数据框函数
当我们需要重复使用dplyr动词时,就可以考虑编写一个数据框函数。它们以数据框作为第一个参数,后面跟着一些额外的参数用于说明如何处理,并输出一个数据框或向量。
25.3.1 间接引用与整洁求值
当开始编写使用 dplyr 动词的函数时,我们很快就会遇到间接引用的问题。下面用一个简单函数grouped_mean()来说明。该函数的目标是根据 group_var 分组并计算 mean_var 的平均值:
grouped_mean <- function(df, group_var, mean_var) {
df |>
group_by(group_var) |>
summarize(mean(mean_var))
}看起来没啥问题,但是运行时会得到一个错误:
diamonds |> grouped_mean(cut, carat)
#> Error in `group_by()`:
#> ! Must group by variables found in `.data`.
#> ✖ Column `group_var` is not found.不难发现,此函数似乎是想寻找本应在函数定义中充当变量的group_var。dplyr 默认直接捕获函数参数中写死的变量名(如 group_var),而不是评估新传入的参数名(如 group 和 x)。这就是“间接引用”。它产生的原因是 dplyr 采取“整洁求值”(tidy evaluation)的规则,本意是方便我们在数据框中直接引用变量名而无需特别处理,但在封装成函数时却成了绊脚石。
好消息是,dplyr提供了解决方案,称为 embracing 🤗。embracing 将变量包裹在双层大括号中,例如 var 写成 { var },意为使用参数中的值,而不是把参数本身当作变量名。
因此,要让 grouped_mean() 正确工作,我们需要用 { } 包裹 group_var 和 mean_var:
grouped_mean <- function(df, group_var, mean_var) {
df |>
group_by({{ group_var }}) |>
summarize(mean({{ mean_var }}))
}
df |> grouped_mean(group, x)
#> # A tibble: 1 × 2
#> group `mean(x)`
#> <dbl> <dbl>
#> 1 1 10成功!
25.3.2 什么时候使用 embracing?
经过上节解释不难看出,编写数据框函数的关键是确定哪些函数的参数需要 embracing,而这可以从文档中查到 。
大体分为两类:
- 数据掩码(Data-masking):
arrange()、filter()、summarize()等对变量计算的函数。 - 整洁选择(Tidy-selection):
select()、relocate()、rename()等选择变量的函数。
25.3.3 常见用例
如果你在处理数据时经常执行相同的某种汇总操作,便可以考虑将它们封装成一个辅助函数:
summary6 <- function(data, var) {
data |> summarize(
min = min({{ var }}, na.rm = TRUE),
mean = mean({{ var }}, na.rm = TRUE),
median = median({{ var }}, na.rm = TRUE),
max = max({{ var }}, na.rm = TRUE),
n = n(),
n_miss = sum(is.na({{ var }})),
.groups = "drop"
)
}
diamonds |> summary6(carat)
#> # A tibble: 1 × 6
#> min mean median max n n_miss
#> <dbl> <dbl> <dbl> <dbl> <int> <int>
#> 1 0.2 0.798 0.7 5.01 53940 0将
summarize()封装成辅助函数时,建议设置.groups = "drop",以清除所有分组属性,将数据框还原为普通表格。
再来一例,下面这个新定义函数是 count() 的增强版,能够同时计算比例:
count_prop <- function(df, var, sort = FALSE) {
df |>
count({{ var }}, sort = sort) |>
mutate(prop = n / sum(n))
}
diamonds |> count_prop(clarity)
#> # A tibble: 8 × 3
#> clarity n prop
#> <ord> <int> <dbl>
#> 1 I1 741 0.0137
#> 2 SI2 9194 0.170
#> 3 SI1 13065 0.242
#> 4 VS2 12258 0.227
#> 5 VS1 8171 0.151
#> 6 VVS2 5066 0.0939
#> # ℹ 2 more rows这个函数有三个参数:df、var 和 sort,只有 var 需要 embracing,因为它传递给了 count()。注意, sort 设置了默认值,如果用户未提供值,则默认为 FALSE。
以上例子都是把数据框作为第一个参数,但如果反复使用相同的数据,也可以硬编码它。例如下面这个函数可直接定向使用 flights 数据集,定向选择 time_hour、carrier 和 flight:
subset_flights <- function(rows, cols) {
flights |>
filter({{ rows }}) |>
select(time_hour, carrier, flight, {{ cols }})
}25.3.4 数据掩码 vs. 整洁选择
有时我们会想在使用 data-masking 的函数中选择变量。例如想定义一个 count_missing() 来统计缺失观测值的数量,可能会像这样写:
count_missing <- function(df, group_vars, x_var) {
df |>
group_by({{ group_vars }}) |>
summarize(
n_miss = sum(is.na({{ x_var }})),
.groups = "drop"
)
}
flights |>
count_missing(c(year, month, day), dep_time)
#> Error in `group_by()`:
#> ℹ In argument: `c(year, month, day)`.
#> Caused by error:
#> ! `c(year, month, day)` must be size 336776 or 1, not 1010328.函数报错了,因为 group_by() 属于 data-masking,而不是 tidy-selection。此时可以在对应函数里套一个 pick() 函数,就能让我们在 data-masking 函数中使用 tidy-selection 方式:
count_missing <- function(df, group_vars, x_var) {
df |>
group_by(pick({{ group_vars }})) |>
summarize(
n_miss = sum(is.na({{ x_var }})),
.groups = "drop"
)
}
flights |>
count_missing(c(year, month, day), dep_time)
#> # A tibble: 365 × 4
#> year month day n_miss
#> <int> <int> <int> <int>
#> 1 2013 1 1 4
#> 2 2013 1 2 8
#> 3 2013 1 3 10
#> 4 2013 1 4 6
#> 5 2013 1 5 3
#> 6 2013 1 6 1
#> # ℹ 359 more rowspick() 的另一个实用场景是构建二维计数表。比如下面我们将全部行列变量计数,然后用 pivot_wider() 将计数转换成网格:
count_wide <- function(data, rows, cols) {
data |>
count(pick(c({{ rows }}, {{ cols }}))) |>
pivot_wider(
names_from = {{ cols }},
values_from = n,
names_sort = TRUE,
values_fill = 0
)
}
diamonds |> count_wide(c(clarity, color), cut)
#> # A tibble: 56 × 7
#> clarity color Fair Good `Very Good` Premium Ideal
#> <ord> <ord> <int> <int> <int> <int> <int>
#> 1 I1 D 4 8 5 12 13
#> 2 I1 E 9 23 22 30 18
#> 3 I1 F 35 19 13 34 42
#> 4 I1 G 53 19 16 46 16
#> 5 I1 H 52 14 12 46 38
#> 6 I1 I 34 9 8 24 17
#> # ℹ 50 more rows25.4 绘图函数
讲完数据框函数,现在来看看如何定义绘图函数。 aes() 同样是一个数据掩码函数(data-masking function),所以技巧大差不差。
打个比方,假设我们需要制作很多直方图:
diamonds |>
ggplot(aes(x = carat)) +
geom_histogram(binwidth = 0.1)
diamonds |>
ggplot(aes(x = carat)) +
geom_histogram(binwidth = 0.05)如果可以把这个过程封装成一个 histogram 函数,那岂不是方便多了?确实很容易实现:
histogram <- function(df, var, binwidth = NULL) {
df |>
ggplot(aes(x = {{ var }})) +
geom_histogram(binwidth = binwidth)
}
diamonds |> histogram(carat, 0.1)这样运行后便可得到一个关于钻石克拉的直方图。
上面自定义的histogram() 返回的是一个 ggplot2 图表对象,这意味着我们仍然可以像平常一样添加其它组件,只要记得把 |> 换成 +。比如添加标签:
diamonds |>
histogram(carat, 0.1) +
labs(x = "Size (in carats)", y = "Number of diamonds")25.4.1 更多变量
基于新函数的框架,我们可以轻松地添加更多变量。例如,若想快速查看一个数据集是否呈线性关系,可以创建新函数linearity_check()来叠加一条平滑曲线和一条直线:
linearity_check <- function(df, x, y) {
df |>
ggplot(aes(x = {{ x }}, y = {{ y }})) +
geom_point() +
geom_smooth(method = "loess", formula = y ~ x, color = "red", se = FALSE) +
geom_smooth(method = "lm", formula = y ~ x, color = "blue", se = FALSE)
}
starwars |>
filter(mass < 1000) |>
linearity_check(mass, height)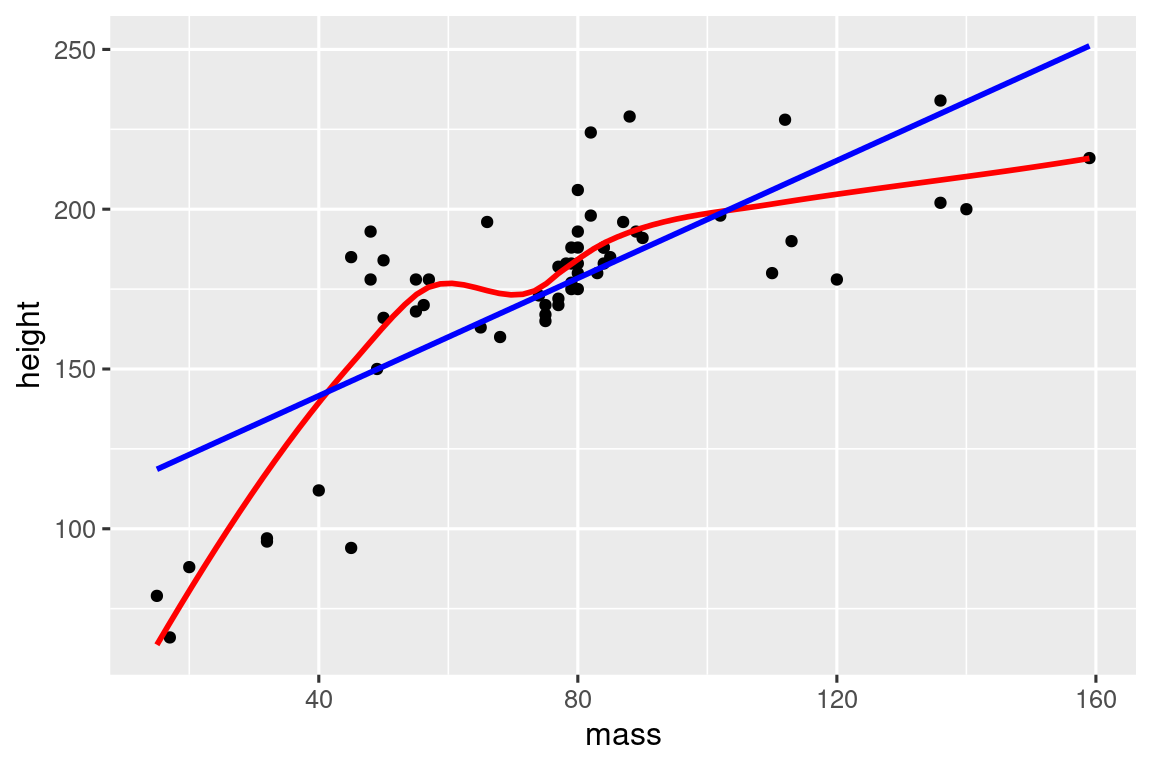
如此便可画出星球大战人物的身高与体重散点图,显示出正相关关系。红色曲线为平滑趋势线,蓝色线为最佳拟合直线。
对于过于庞大的数据集,为避免图像重叠,不妨通过新定义使用六边形图来展示散点图的密度:
hex_plot <- function(df, x, y, z, bins = 20, fun = "mean") {
df |>
ggplot(aes(x = {{ x }}, y = {{ y }}, z = {{ z }})) +
stat_summary_hex(
aes(color = after_scale(fill)),
bins = bins,
fun = fun,
)
}
diamonds |> hex_plot(carat, price, depth)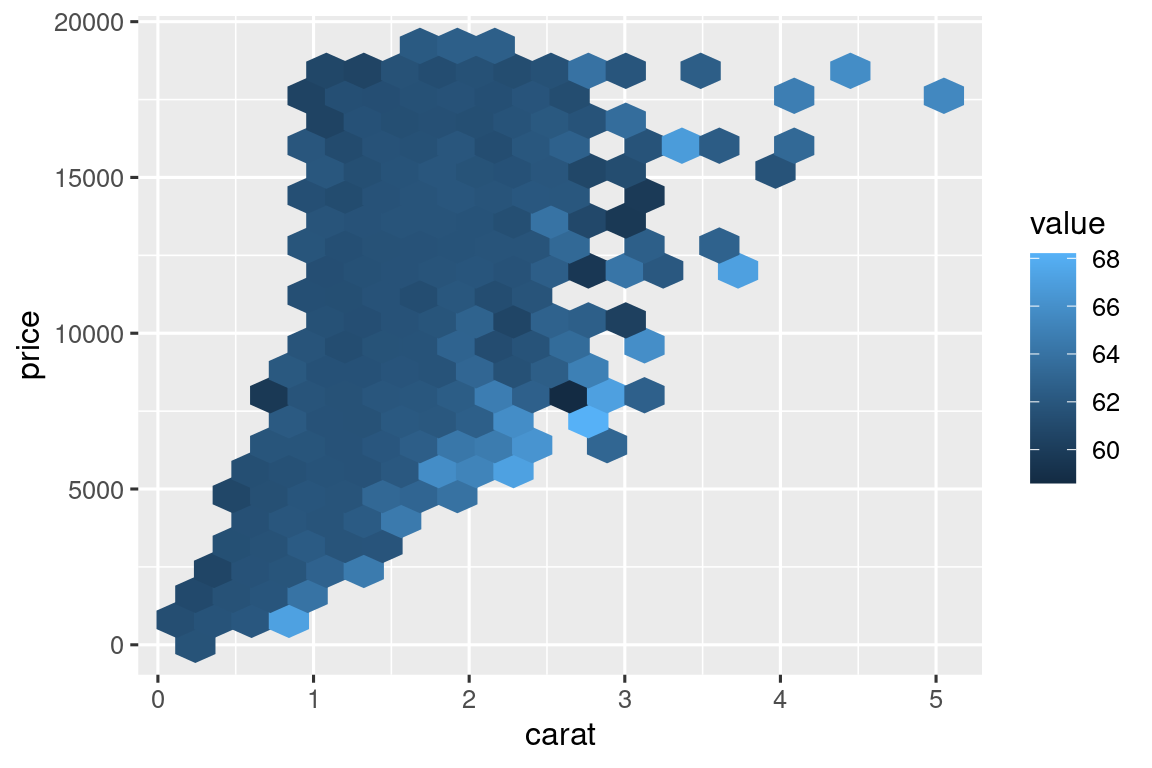
25.4.2 与 tidyverse 结合
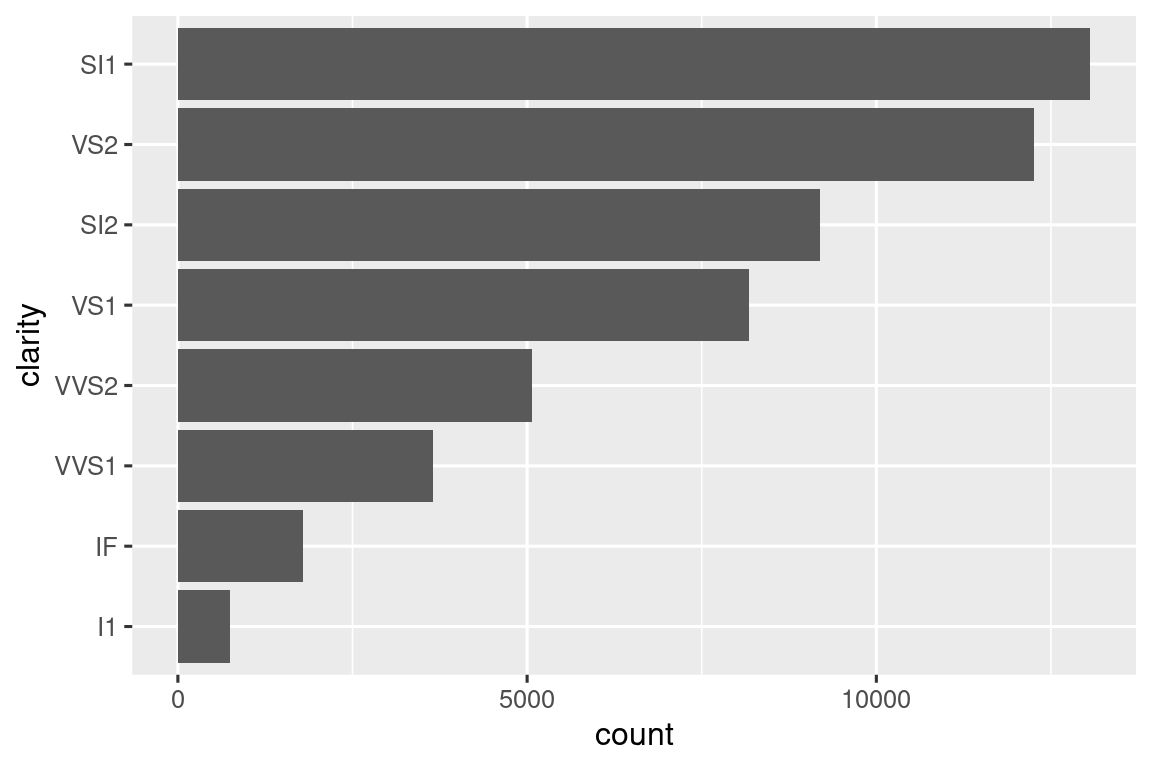
高效的绘图函数一般都将数据处理和 ggplot2 相结合。例如使用 fct_infreq()函数生成一个按频率排序的垂直柱状图,同时要让频率最高的在顶部,则可定义sorted_bars():
sorted_bars <- function(df, var) {
df |>
mutate({{ var }} := fct_rev(fct_infreq({{ var }}))) |>
ggplot(aes(y = {{ var }})) +
geom_bar()
}
diamonds |> sorted_bars(clarity)注意新的运算符
:=(海象运算符 walrus operator)。由于我们需要根据用户输入的数据生成变量名,且变量名需要放在等号
=的左边,但 R 的语法不允许=左边是表达式。所以此处必须使用:=替代=。
25.4.3 图表标签
还记得我们之前写的直方图函数吗?
histogram <- function(df, var, binwidth = NULL) {
df |>
ggplot(aes(x = {{ var }})) +
geom_histogram(binwidth = binwidth)
}如果图表能自动标注变量名和 bin 宽度,岂不是更好?为了解决标注问题,我们可以使用 rlang::englue()。它的作用类似于 str_glue():
- 将
{}中的值插入字符串。 - 识别
{ },并自动插入变量名:
histogram <- function(df, var, binwidth) {
label <- rlang::englue("A histogram of {{ var }} with binwidth {binwidth}")
df |>
ggplot(aes(x = {{ var }})) +
geom_histogram(binwidth = binwidth) +
labs(title = label)
}
diamonds |> histogram(carat, 0.1)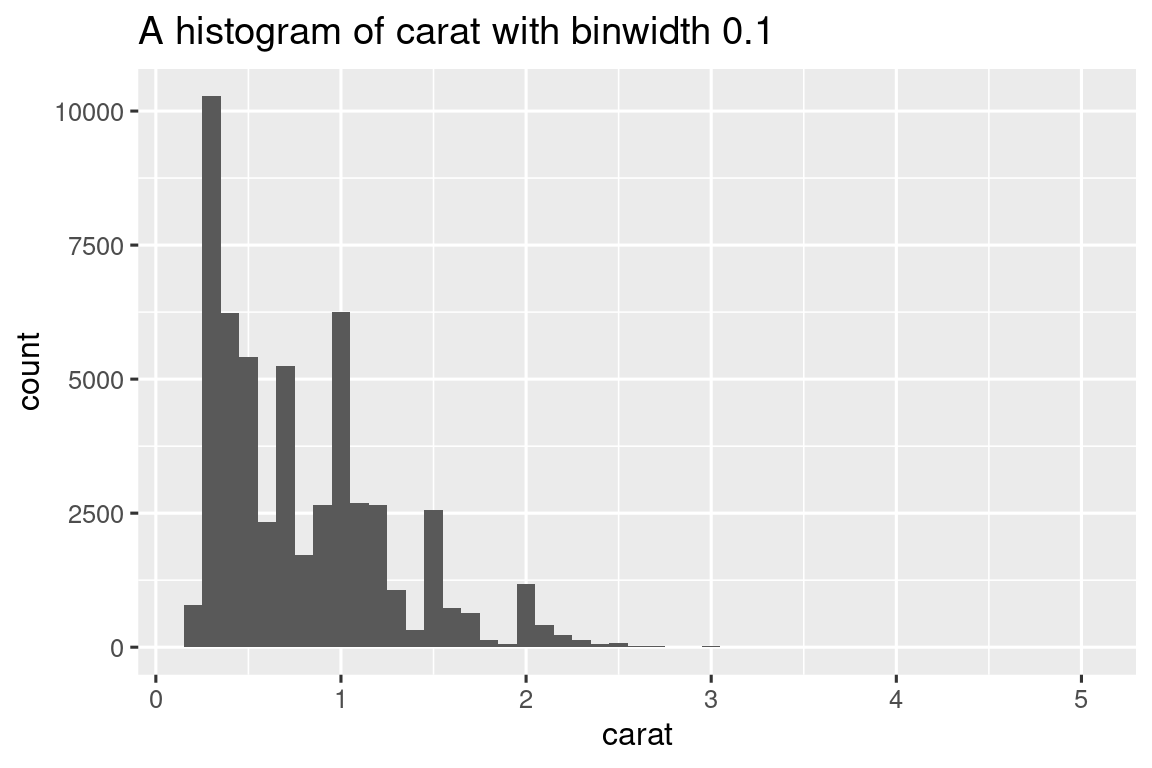
25.5 代码风格规范
虽然函数或参数命名的规范性不会影响R对其的执行,但恰当的命名对代码的可读性至关重要。理想的函数名应当简洁明了,能准确传达函数的功能。
通常而言,函数名宜采用动词,参数名宜采用名词。当然也有例外,比如某些约定成俗的名词,如均值函数mean()就比compute_mean()更合适。开发者应当灵活判断,大胆命名。
列出一些命名的反面示例,仅供参考:
# 名称过短
f()
# 非动词且表意模糊
my_awesome_function()
# 正面示范(名称虽长但语义清晰)
impute_missing()
collapse_years()同样地,代码中空格的使用规范不影响使用效果,但会影响代码的可读性。务必遵循第4章的格式规范,并特别注意:
function()后必须紧跟花括号{},且函数体需缩进两个空格。建议在
{ }内部添加额外空格(如{ color }),能显著提醒读者此处存在特殊语法操作。