20 电子表格
20.1 引言
本书第7章已经讲解了如何从纯文本文件(如 .csv 和 .tsv)导入数据。现在是时候学习如何从电子表格中提取数据了,例如 Excel 文件和 Google 表格。本章内容在第7章基础上进行拓展。
如果习惯使用电子表格来整理数据,本书强烈推荐阅读 Karl Broman 和 Kara Woo 撰写的论文《Data Organization in Spreadsheets》https://doi.org/10.1080/00031305.2017.1375989。
20.2 Excel
Microsoft Excel 是一种广泛使用的电子表格软件,数据以工作表的形式组织在电子表格文件中。
20.2.1 前置包
本节介绍如何使用 readxl 包在 R 中加载 Excel 电子表格数据。该包不属于 tidyverse 核心包,因此需要显式加载,但在安装 tidyverse 时会自动安装。此外还会用到 writexl 包,该包可以用于创建 Excel 电子表格。
library(readxl)
library(tidyverse)
library(writexl)20.2.2 入门
readxl 提供的多数函数可将 Excel 表格加载到 R 中:
read_xls()读取.xls格式的 Excel 文件;read_xlsx()读取.xlsx格式的 Excel 文件;read_excel()可读取.xls和.xlsx两种格式的文件,它会根据输入自动识别文件类型。
这些函数语法类似于其他读取函数,如 read_csv()、read_table() 等。
20.2.3 读取 Excel 表格
下图是一个Excel示例表格,包含6个学生的学号、姓名、食物喜好、就餐计划和年龄等信息。。该文件可通过以下链接下载:https://docs.google.com/spreadsheets/d/1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w/。
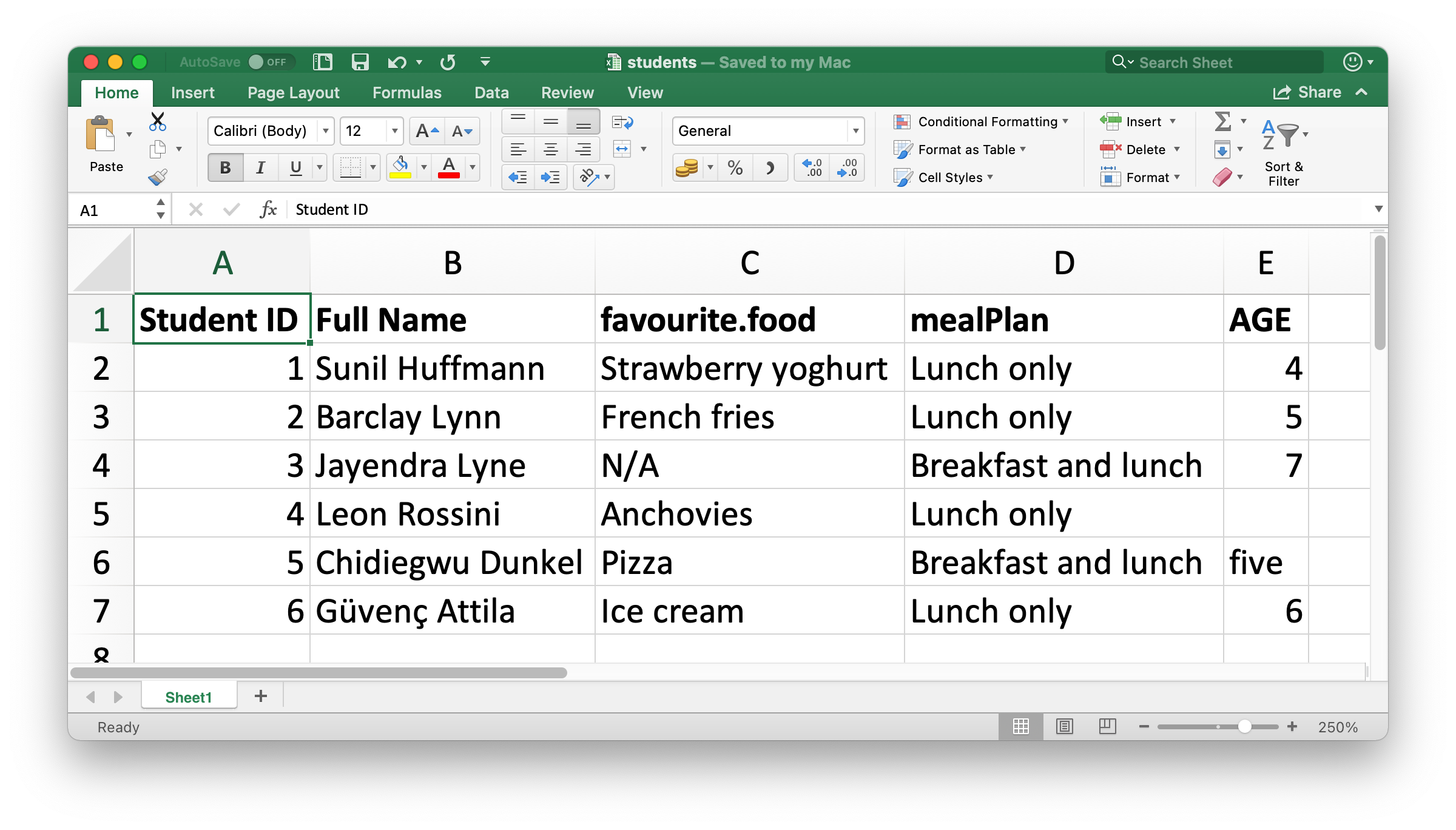
如下将表格导入R,输出结果为一个 tibble,每位学生有 5 个变量:
students <- read_excel("data/students.xlsx")
students
#> # A tibble: 6 × 5
#> `Student ID` `Full Name` favourite.food mealPlan AGE
#> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
#> 2 2 Barclay Lynn French fries Lunch only 5
#> 3 3 Jayendra Lyne N/A Breakfast and lunch 7
#> 4 4 Leon Rossini Anchovies Lunch only <NA>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
#> 6 6 Güvenç Attila Ice cream Lunch only 6导入后观察,发现有格式问题:
- 列名格式不一致。可通过
col_names参数自定义列名(书中推荐使用snake_case命名法):
read_excel(
"data/students.xlsx",
col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age")
)然而改完后,表头行(即列名行)成了数据的第 1 行。可使用 skip 参数跳过该行:
read_excel(
"data/students.xlsx",
col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"),
skip = 1
)favourite_food中有值为 “N/A”,且未被识别为缺失值 NA(如果被识别则显示<NA>)。可通过na参数指定缺失值字符:
read_excel(
"data/students.xlsx",
col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"),
skip = 1,
na = c("", "N/A")
)age被读取为字符型,但应为数值型。可通过col_types参数自定义列类型:
read_excel("data/students.xlsx",
col_names = c(...),
skip = 1,
na = c("", "N/A"),
col_types = c("numeric", "text", "text", "text", "numeric"))可用选项包括:“skip”、“guess”、“logical”、“numeric”、“date”、“text”、“list”。
20.2.4 读取工作表
与纯文本文件相比,电子表格支持多个工作表(worksheets)。下图展示了包含多个工作表的 Excel 文件。数据来自 palmerpenguins 包,可通过此链接下载示例表格:https://docs.google.com/spreadsheets/d/1aFu8lnD_g0yjF5O-K6SFgSEWiHPpgvFCF0NY9D6LXnY/。
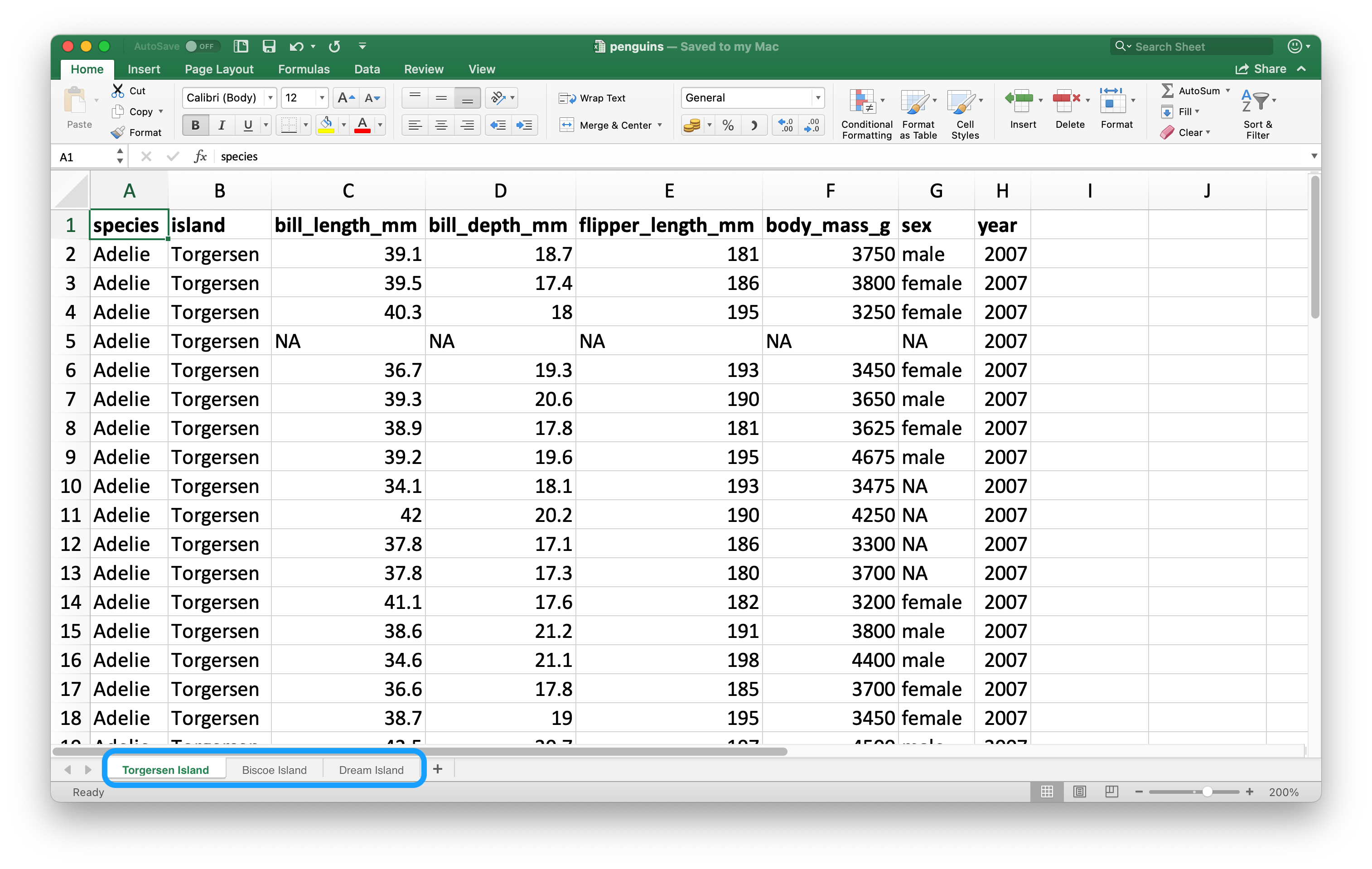
使用read_excel()函数的sheet参数可以选择读取哪个工作表,默认读取第一个。
read_excel("data/penguins.xlsx", sheet = "Torgersen Island")使用 excel_sheets() 可查看所有工作表名称:
excel_sheets("data/penguins.xlsx")
#> [1] "Torgersen Island" "Biscoe Island" "Dream Island"随后分别读取:
penguins_biscoe <- read_excel("data/penguins.xlsx", sheet = "Biscoe Island", na = "NA")
penguins_dream <- read_excel("data/penguins.xlsx", sheet = "Dream Island", na = "NA")使用 bind_rows() 合并三张表:
penguins <- bind_rows(penguins_torgersen, penguins_biscoe, penguins_dream)20.2.5 读取工作表的特定部分
很多 Excel 表格不仅包含数据,还包含注释等非数据内容。比如下图,数据前后有冗余文本行。
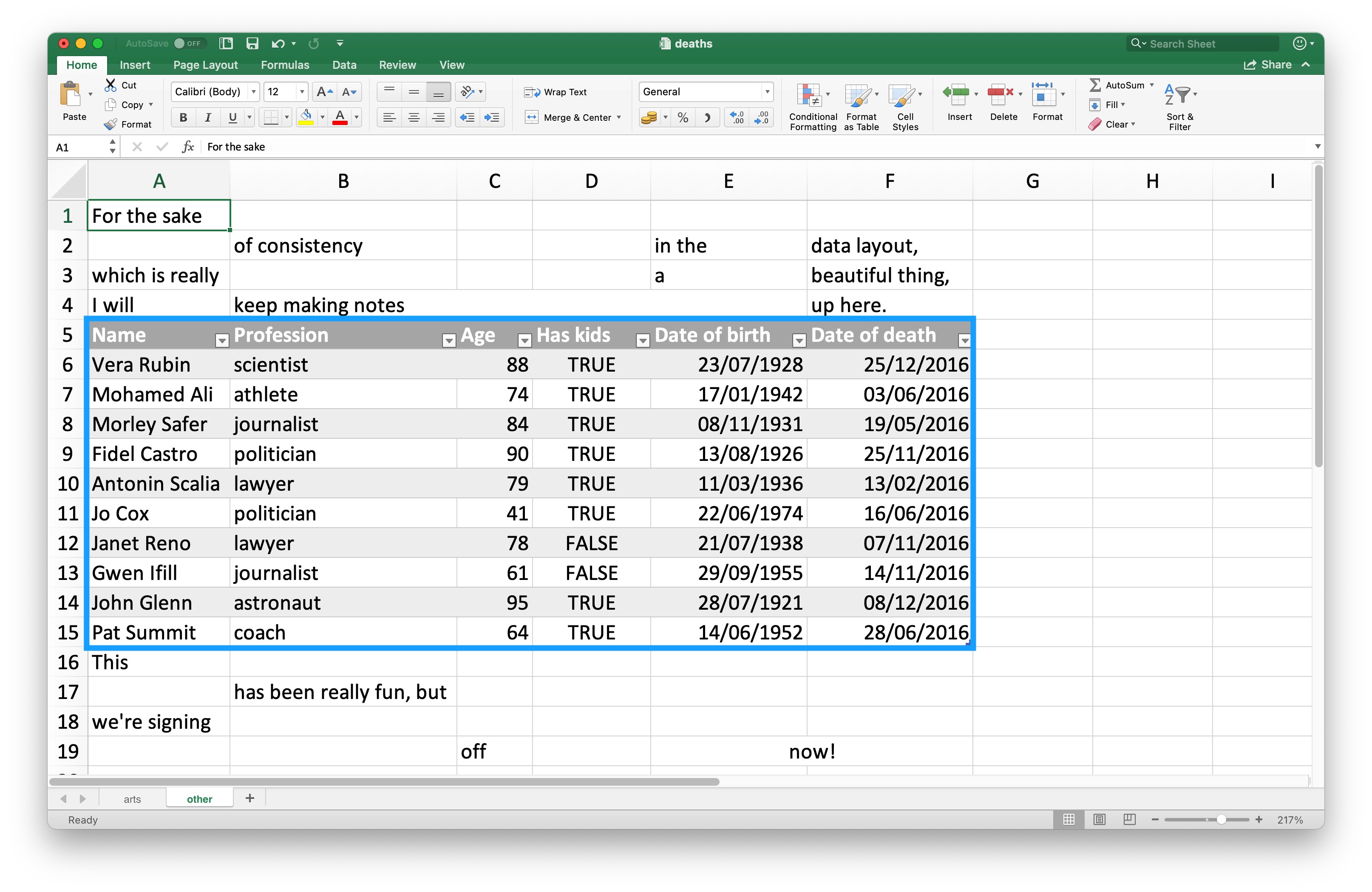
此表格可通过 readxl_example() 函数定位:
deaths_path <- readxl_example("deaths.xlsx")
deaths <- read_excel(deaths_path)使用 range 参数可仅读取所需区域。例如数据从 A5 到 F15:
read_excel(deaths_path, range = "A5:F15")20.2.6 数据类型
CSV 中所有值为字符串,而 Excel 则较为复杂:
- 布尔值(TRUE、FALSE、NA)
- 数字(如 10 或 10.5)
- 日期时间(如 2021/11/1 15:00)
- 文本(如 “ten”)
Excel 内部不区分整数,所有数字均为浮点数。
readxl 会自动猜测列类型。推荐如下工作流程:
- 初步读取并让
readxl猜测; - 检查类型;
- 若有瑕疵,重新指定
col_types。
如某列类型混合(数值、文本、日期),可设为 "list",每个单元格为一个单值向量。
20.2.7 写入 Excel
创建一个小数据框:
bake_sale <- tibble(
item = factor(c("brownie", "cupcake", "cookie")),
quantity = c(10, 5, 8)
)使用 writexl::write_xlsx() 写入 Excel:
write_xlsx(bake_sale, path = "data/bake-sale.xlsx")读取回来:
read_excel("data/bake-sale.xlsx")注意重新读取时,数据类型信息会丢失,因此 Excel 文件并不适合用于缓存中间结果。
20.2.8 格式化输出
writexl 是轻量级写入工具,若需更多功能(如写入多个工作表、样式设置),推荐使用 openxlsx 包。使用方法详见其官方文档:openxlsx formatting。
该包不属于 tidyverse,其函数风格与 tidyverse 不同。
20.3 Google 表格
Google 表格(Google Sheets)是另一种广泛使用的电子表格程序。它是免费、基于网页的。和 Excel 一样,Google 表格中的数据以工作表(也称为 sheets)的形式组织在电子表格文件中。
20.3.1 前置包
使用 googlesheets4 包从 Google 表格中加载数据。该包同样不是 tidyverse 的核心包,因此也需要显式加载。
library(googlesheets4)
library(tidyverse)关于包名的一点说明:googlesheets4 使用的是 Google Sheets API 的第 4 版(v4)来为 Google 表格提供 R 接口,因此包名中有 “4”。
20.3.2 入门
googlesheets4 包的主要函数是 read_sheet(),它用于从 URL 或文件 ID 中读取 Google 表格。该函数也可以写成 range_read()。
也可以使用 gs4_create() 创建一个全新的表格,或者使用 sheet_write()将数据写入已有表格。
20.3.3 读取 Google 表格
下图是Google 表格呈现的20.2.3节数据集。
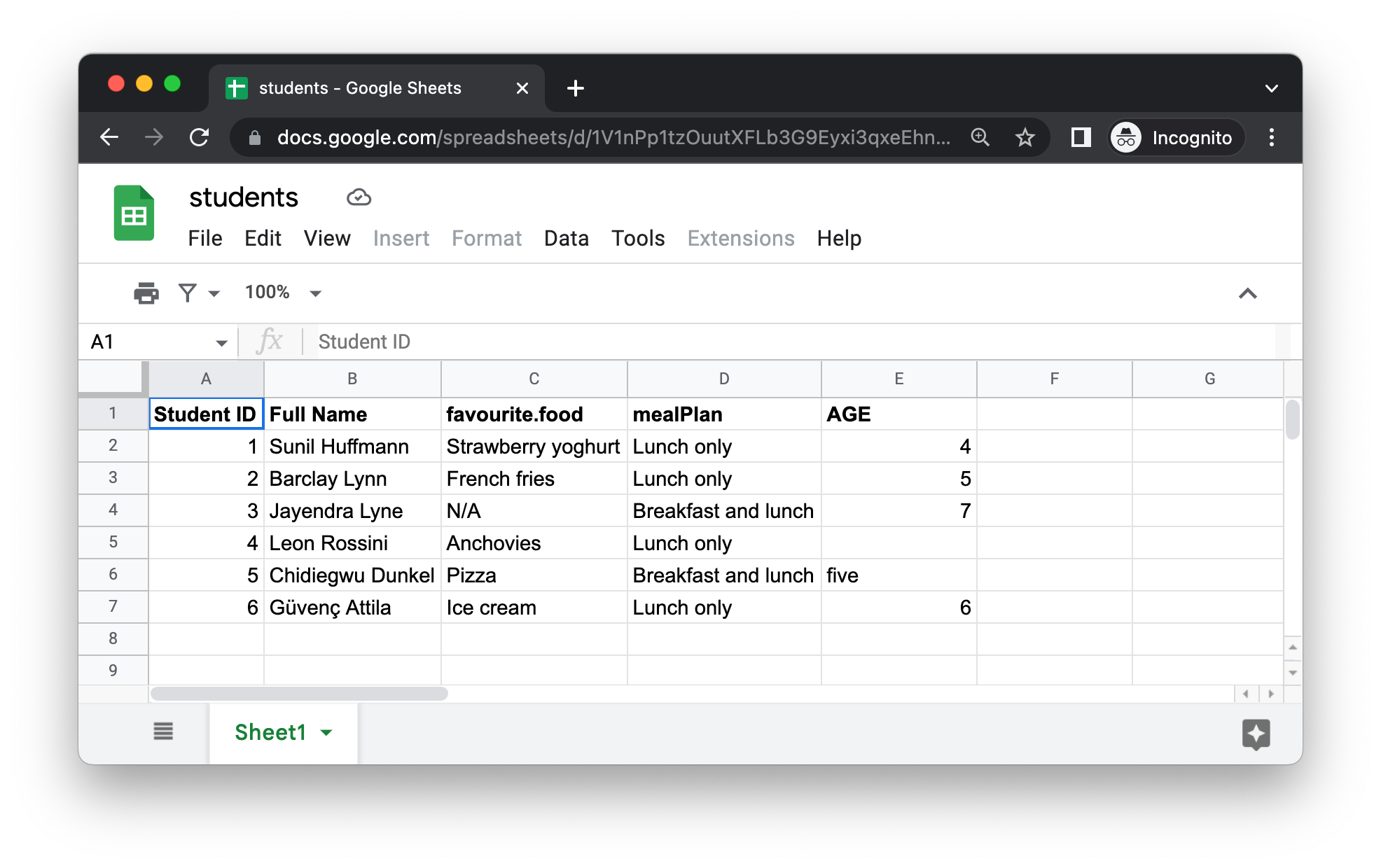
URL 是 read_sheet() 的第一个参数,可返回一个 tibble:
https://docs.google.com/spreadsheets/d/1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w
URL 不太方便操作,因此通常通过 ID 来识别一个表格。所谓 ID 就是 URL 的后半段。
gs4_deauth()
students_sheet_id <- "1V1nPp1tzOuutXFLb3G9Eyxi3qxeEhnOXUzL5_BcCQ0w"
students <- read_sheet(students_sheet_id)
#> ✔ Reading from students.
#> ✔ Range Sheet1.
students
#> # A tibble: 6 × 5
#> `Student ID` `Full Name` favourite.food mealPlan AGE
#> <dbl> <chr> <chr> <chr> <list>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only <dbl>
#> 2 2 Barclay Lynn French fries Lunch only <dbl>
#> 3 3 Jayendra Lyne N/A Breakfast and lunch <dbl>
#> 4 4 Leon Rossini Anchovies Lunch only <NULL>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch <chr>
#> 6 6 Güvenç Attila Ice cream Lunch only <dbl> 与 read_excel()类似 , read_sheet() 同样有关于列名、NA 字符串和列类型的一系列操作:
students <- read_sheet(
students_sheet_id,
col_names = c("student_id", "full_name", "favourite_food", "meal_plan", "age"),
skip = 1,
na = c("", "N/A"),
col_types = "dcccc"
)
#> ✔ Reading from students.
#> ✔ Range 2:10000000.
students
#> # A tibble: 6 × 5
#> student_id full_name favourite_food meal_plan age
#> <dbl> <chr> <chr> <chr> <chr>
#> 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
#> 2 2 Barclay Lynn French fries Lunch only 5
#> 3 3 Jayendra Lyne <NA> Breakfast and lunch 7
#> 4 4 Leon Rossini Anchovies Lunch only <NA>
#> 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
#> 6 6 Güvenç Attila Ice cream Lunch only 6注意这里使用简写方式定义了列类型,col_types = "dcccc"表示 “浮点数、字符、字符、字符、字符”。
同样也可以读取 Google 表格中的某个单独工作表。比如 penguins 表格中的 "Torgersen Island" 工作表:
penguins_sheet_id <- "1aFu8lnD_g0yjF5O-K6SFgSEWiHPpgvFCF0NY9D6LXnY"
read_sheet(penguins_sheet_id, sheet = "Torgersen Island")用 sheet_names() 查看该 Google 表格中的所有工作表名称:
sheet_names(penguins_sheet_id)
#> [1] "Torgersen Island" "Biscoe Island" "Dream Island"read_sheet() 函数的range参数可用于定位表格范围,读取特定部分数据:
deaths_url <- gs4_example("deaths")
deaths <- read_sheet(deaths_url, range = "A5:F15")20.3.4 写入 Google 表格
使用 write_sheet() 将 R 中的数据写入 Google 表格。第一个参数是要写入的数据框,第二个参数是目标 Google 表格的名称:
write_sheet(bake_sale, ss = "bake-sale")如果要将数据写入某个特定的工作表(sheet),可以使用 sheet 参数指定:
write_sheet(bake_sale, ss = "bake-sale", sheet = "Sales")20.3.5 身份验证
要读取私密表格或写入任何Google表格,需要进行身份验证,以便 googlesheets4 能访问并管理表格。
在尝试读取一个需要验证的表格时,googlesheets4 会提示跳转一个网页,登录 Google 账户进行授权。
如果希望指定具体的 Google 账户、身份验证作用域等,可以使用 gs4_auth(),例如:
gs4_auth(email = "jiading@gmail.com")