19 连接
19.1 引言
在数据分析中,通常会有多个数据框,并将它们合并关联起来以解决问题。本章介绍两种重要的连接操作:
- 变形连接(mutating joins):从另一个数据框中提取匹配行的变量,添加到当前数据框中。
- 筛选连接(filtering joins):根据是否在另一个数据框中存在匹配项,筛选当前数据框的行。
本章使用 nycflights13 包中的五个相关数据集,并通过 dplyr 包中的连接函数进行分析。
library(tidyverse)
library(nycflights13)19.2 键
要理解连接操作,首先得了解两个表格是如何通过各自的一对键(Keys)关联起来的。
每次连接操作都涉及一对键:主键(primary key) 和 外键(foreign key)。
- 主键是唯一标识表中每一行的变量(或变量组合)。如果需要多个变量来唯一标识一行数据,则称为复合主键。
- 外键是另一个表中的变量,值对应于该表的主键,用于建立连接关系。
例如,在 nycflights13 中:
airlines表中,每家航空公司由其两位字母的代码carrier唯一标识,因此carrier是主键。weather表中,每条记录由origin(机场)和time_hour(时间)联合标识,是复合主键。
而在 flights 表中,很多列是外键,仅举三例:
tailnum对应planes的主键。origin和dest都对应airports的主键。origin和time_hour联合对应weather表中的复合主键。
识别出主键之后,最好检查它们是否真的可以唯一标识每一行。方法之一是使用 count() 看看有没有重复。
比如 planes 和 weather 表的主键就没有重复:
> planes |>
count(tailnum) |>
filter(n > 1)
> weather |>
count(time_hour, origin) |>
filter(n > 1)输出结果都是空的,说明每个主键组合只出现了一次。
还需要如下检查主键是否包含缺失值,有NA就无法进行唯一标识:
planes |> filter(is.na(tailnum))
weather |> filter(is.na(time_hour) | is.na(origin))到目前为止我们还没有确定 flights 表的主键。经过探索发现,用 time_hour(小时级别的出发时间)、carrier(航空公司代码)和 flight(航班号)这三列可以唯一标识每一条航班记录:
flights |>
count(time_hour, carrier, flight) |>
filter(n > 1)结果是 0,说明组合后唯一。
不过,唯一性并不意味着就是实用的主键。比如 airports 表中的 alt(海拔)和 lat(纬度)的组合也可能唯一,但显然不是标识机场的好方式。因此,仅凭数据很难判断一个键是否合理。不过话又说回来,在 flights 中,使用上面的组合在逻辑上倒也说得通。
尽管如此,从严谨性出发,最好选择创建一个简单的替代键(Surrogate Keys),比如用行号来唯一标识每条记录:
flights2 <- flights |>
mutate(id = row_number(), .before = 1)这样就多了一个 id 字段,用于唯一识别每一行,可作为主键。这对于人与人沟通时尤其方便——就好比说“去看看第 2001 号航班”比“去查 UA430 在 2013-01-03 早上 9 点的航班”更简单。
19.3 基本连接
dplyr 提供了六种连接函数:left_join()、inner_join()、right_join()、full_join()、semi_join() 和 anti_join()。它们的接口相同,都接受一对数据框(x 和 y),返回一个数据框。输出中的行和列顺序主要由 x 决定。
- 变形连接(mutating join)
变形连接可以将两个数据框中的变量合并。首先通过键匹配观测值,然后将一个数据框中的变量复制到另一个数据框中。
为了更容易观察连接的效果,下面构建一个包含六个变量的简化版 flights 数据集:
flights2 <- flights |>
select(year, time_hour, origin, dest, tailnum, carrier)
flights2
#> # A tibble: 336,776 × 6
#> year time_hour origin dest tailnum carrier
#> <int> <dttm> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA
#> # ℹ 336,770 more rows变形连接最常用 left_join()函数,特点是其输出会保留被连接数据框(x)中的所有行。此函数的主要用途是添加元数据。例如,将航空公司全称name加入 flights2:
flights2 |>
left_join(airlines)
#> Joining with `by = join_by(carrier)`
#> # A tibble: 336,776 × 7
#> year time_hour origin dest tailnum carrier name
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA United Air Lines In…
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA United Air Lines In…
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA American Airlines I…
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 JetBlue Airways
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL Delta Air Lines Inc.
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA United Air Lines In…
#> # ℹ 336,770 more rows当 left_join() 无法为被连接数据框 x 中的某行找到匹配值时,会在新变量中填充NA。例如,tailnum 为 N3ALAA 的飞机在 planes 中没有相关信息:
flights2 |>
filter(tailnum == "N3ALAA") |>
left_join(planes |> select(tailnum, type, engines, seats))
flights2 |>
filter(tailnum == "N3ALAA") |>
left_join(planes |> select(tailnum, type, engines, seats))
#> Joining with `by = join_by(tailnum)`
#> # A tibble: 63 × 9
#> year time_hour origin dest tailnum carrier type engines seats
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr> <int> <int>
#> 1 2013 2013-01-01 06:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> 2 2013 2013-01-02 18:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> 3 2013 2013-01-03 06:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> 4 2013 2013-01-07 19:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> 5 2013 2013-01-08 17:00:00 JFK ORD N3ALAA AA <NA> NA NA
#> 6 2013 2013-01-16 06:00:00 LGA ORD N3ALAA AA <NA> NA NA
#> # ℹ 57 more rowsinner_join()、right_join() 和 full_join() 接口与 left_join() 相同,但保留的行不同:
left_join()保留 x 中所有行right_join()保留 y 中所有行full_join()保留 x 和 y 中所有行inner_join()仅保留在 x 和 y 中都存在的行
- 指定连接键(Specifying join keys)
默认情况下,left_join() 会使用两个数据框中都存在的变量作为连接键,但是如果变量名称相同而实际含义有区别,再使用这种方式显然不合理。例如,尝试将 flights2 与完整的 planes 数据集连接:
flights2 |>
left_join(planes)
#> Joining with `by = join_by(year, tailnum)`
#> # A tibble: 336,776 × 13
#> year time_hour origin dest tailnum carrier type manufacturer
#> <int> <dttm> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA <NA> <NA>
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA <NA> <NA>
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA <NA> <NA>
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 <NA> <NA>
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL <NA> <NA>
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA <NA> <NA>
#> # ℹ 336,770 more rows
#> # ℹ 5 more variables: model <chr>, engines <int>, seats <int>, …此处产生大量缺失是因为连接键 year 的含义在两个数据框中不同。 flights$year 表示飞行年份,而 planes$year 表示飞机制造年份。因此我们希望排除year这个变量,仅以 tailnum 为键,可显式指定join_by(tailnum)来达到此效果:
flights2 |>
left_join(planes, join_by(tailnum))
#> # A tibble: 336,776 × 14
#> year.x time_hour origin dest tailnum carrier year.y
#> <int> <dttm> <chr> <chr> <chr> <chr> <int>
#> 1 2013 2013-01-01 05:00:00 EWR IAH N14228 UA 1999
#> 2 2013 2013-01-01 05:00:00 LGA IAH N24211 UA 1998
#> 3 2013 2013-01-01 05:00:00 JFK MIA N619AA AA 1990
#> 4 2013 2013-01-01 05:00:00 JFK BQN N804JB B6 2012
#> 5 2013 2013-01-01 06:00:00 LGA ATL N668DN DL 1991
#> 6 2013 2013-01-01 05:00:00 EWR ORD N39463 UA 2012
#> # ℹ 336,770 more rows
#> # ℹ 7 more variables: type <chr>, manufacturer <chr>, model <chr>, …注意到,重复的变量名(如 year)会自动添加后缀以区分, 此处为year.x 和 year.y。可通过 suffix 参数自定义后缀。
join_by(tailnum) 的完整写法是 join_by(tailnum == tailnum)。了解完整写法很重要,原因有二:
它明确描述两个表之间的关系——键必须相等,因此称为等值连接(equi join)。
可以指定两个表中不同的连接变量。例如,
flights2与airports可以通过dest或origin连接:
flights2 |>
left_join(airports, join_by(dest == faa))
flights2 |>
left_join(airports, join_by(origin == faa))- 过滤连接(Filtering joins)
顾名思义,过滤连接的主要作用是筛选行。包括两种类型:
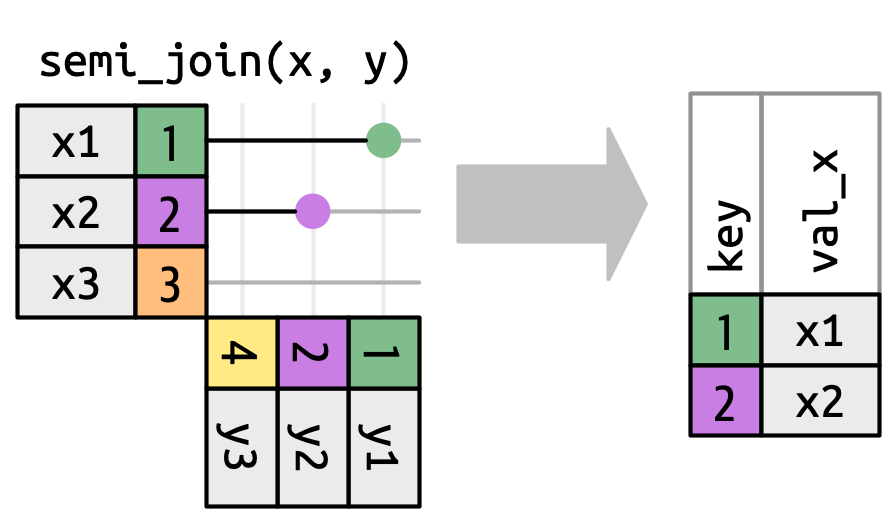
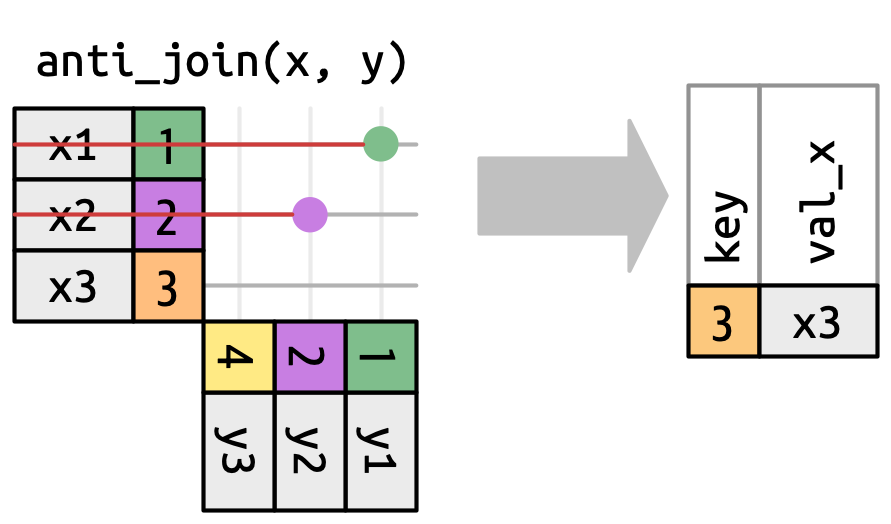
semi_join():保留 x 中与 y 匹配的行anti_join():保留 x 中没有在 y 中匹配的行
例如,使用 semi_join() 筛选出 flights2 中作为起点的机场:
airports |>
semi_join(flights2, join_by(faa == origin))相反,anti_join() 可以找出未匹配上的项,常用于寻找隐式缺失值。例如,查找 flights2 中没有对应目的地机场的航班:
flights2 |>
anti_join(airports, join_by(dest == faa)) |>
distinct(dest)19.4 连接的运作原理
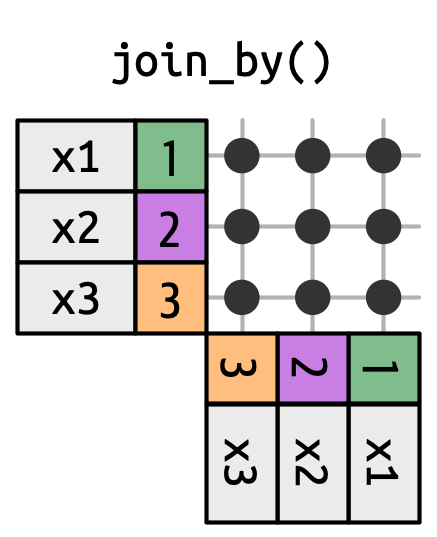
现在让我们深入了解连接是如何运作的,重点在于 x 中的每一行是如何与 y 中的行进行匹配。在下面例子中,只使用一个名为 key 的主键,以及单一值列(分别为val_x 和 val_y),此原理可以推广到多键和多值。
x <- tribble(
~key, ~val_x,
1, "x1",
2, "x2",
3, "x3"
)
y <- tribble(
~key, ~val_y,
1, "y1",
2, "y2",
4, "y3"
)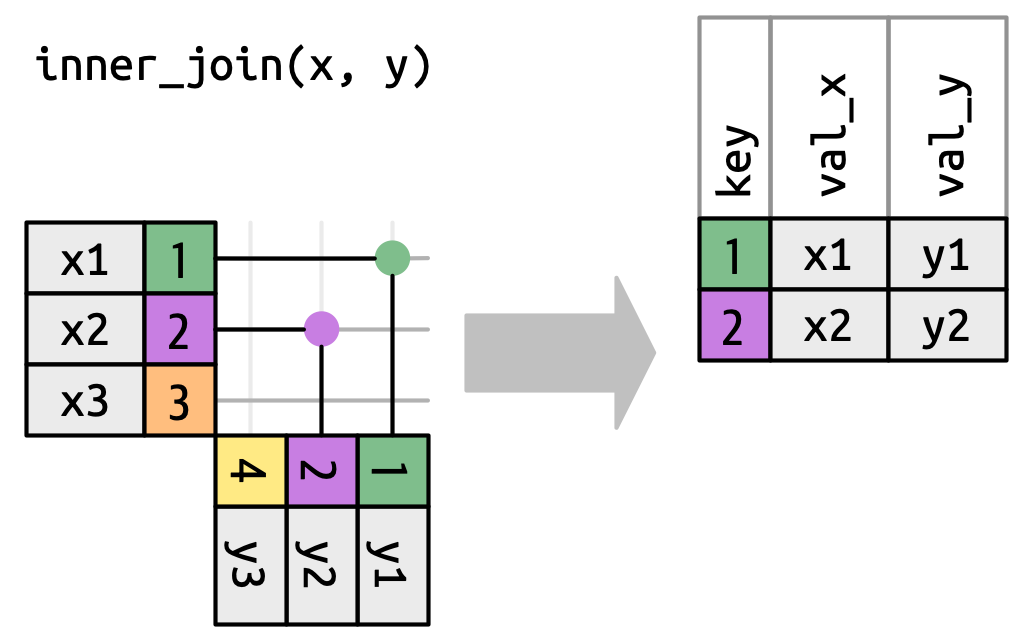
上图展示了 x 和 y 所有潜在匹配的交叉点。这些交叉点由从 x 的每一行水平延伸的线和从 y 的每一行垂直延伸的线组成。输出行主要由 x 决定,因此 x 放在水平位置并对齐。
为了描述某种特定的连接类型,在此用点表示匹配。每一个匹配点都表示一个新的数据框,它包含键、x 的值和 y 的值。 由于上图是内连接(inner join),故只保留交集。键 1 和 2 在 x 和 y 中都存在,因此匹配成功,对应输出中的两行。
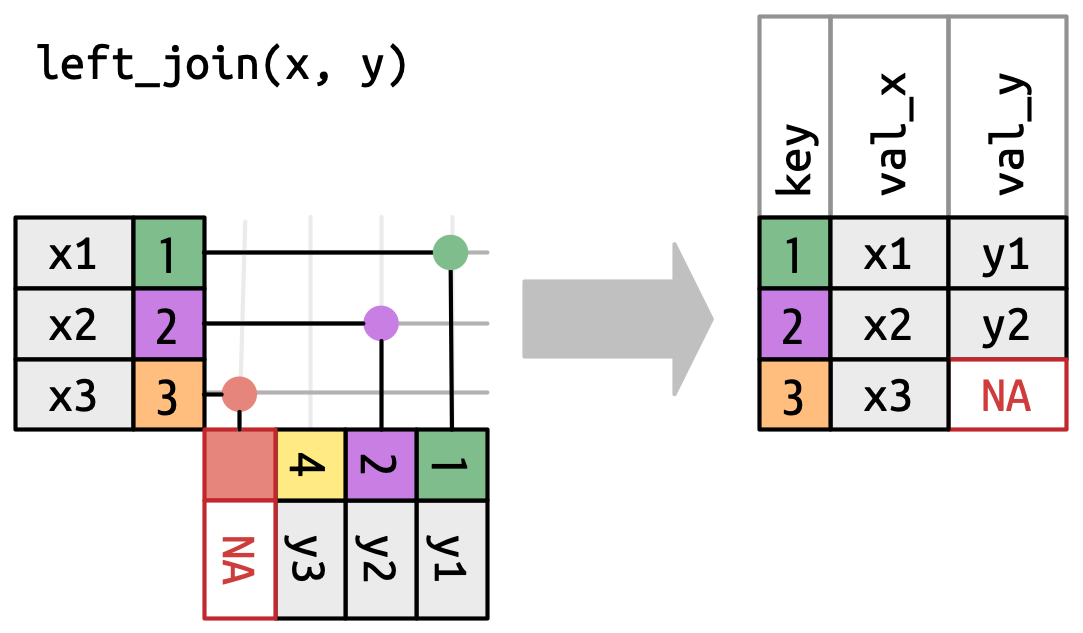
我们可以用同样的原理解释外连接(outer join)。这些连接通过在每个数据框中添加一个虚拟行来实现,虚拟行包含一个能与任何不匹配行相匹配的键,其余字段为 NA。外连接有三种类型:
- 左连接(
left_join)
左连接保留 x 中的所有行。每一行都在输出中保留下来,可以退回而匹配 y 中的虚拟行。键为 3 的行在 y 中无对应项,因此对应的 val_y 为 NA。
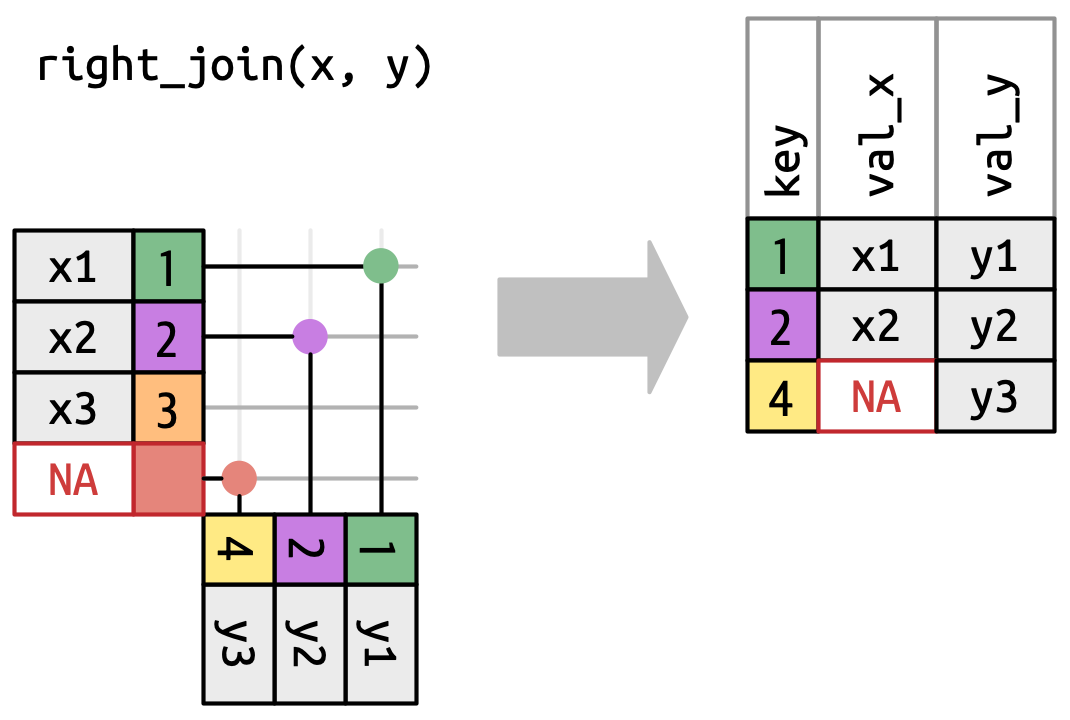
- 右连接(
right_join)
与左连接对应,右连接保留 y 中的所有行。键为 4 的行只在 y 中存在,因此输出中 val_x 为 NA。
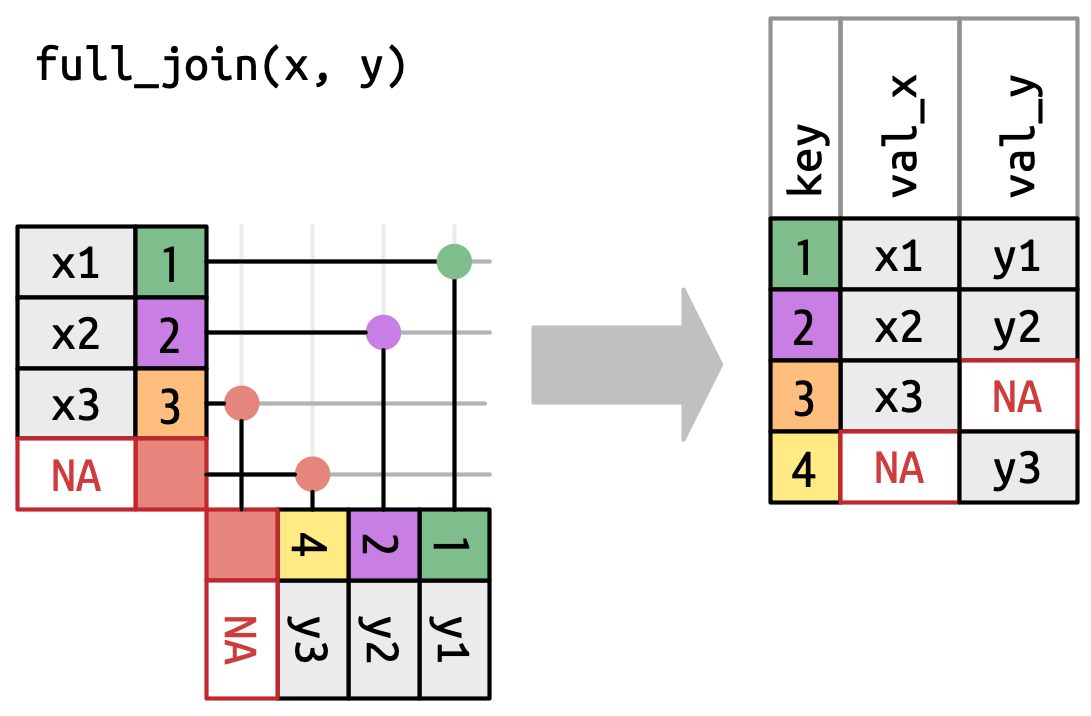
- 全连接(
full_join)
全连接保留 x 和 y 中所有的行。无匹配的部分会填充 NA。
下面的 Venn 图展示了不同连接类型的差异。
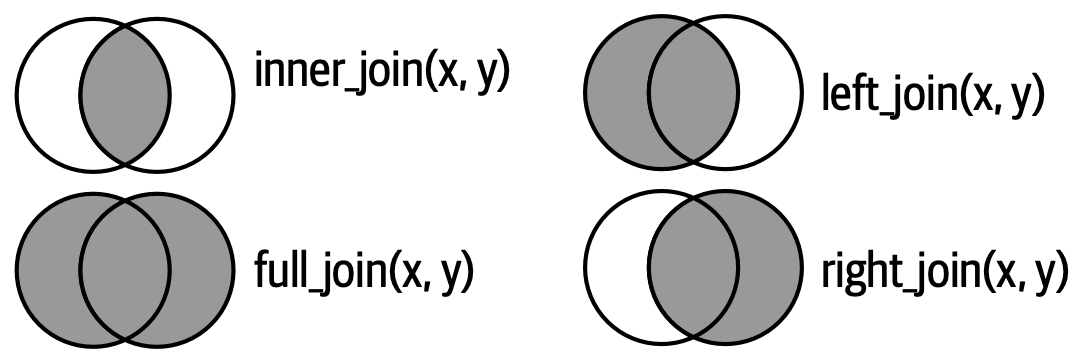
这些连接类型统称为 等值连接(equi joins),即键相等时匹配,是最常见的连接类型。
以上讨论了 x 中的一行最多匹配 y 中一行的情况,现在举例说明匹配多行的情形。
df1 <- tibble(key = c(1, 2, 2), val_x = c("x1", "x2", "x3"))
df2 <- tibble(key = c(1, 2, 2), val_y = c("y1", "y2", "y3"))此例中x1 与 y1 匹配;x2 和 x3 均匹配 y2 和 y3,形成多对多的局面,故运行代码会触发警告,不过仍会有输出,即全部可能的结果。
df1 |>
inner_join(df2, join_by(key))
# A tibble: 5 × 3
key val_x val_y
<dbl> <chr> <chr>
1 1 x1 y1
2 2 x2 y2
3 2 x2 y3
4 2 x3 y2
5 2 x3 y3
warning:
In inner_join(df1, df2, join_by(key)) :
Detected an unexpected many-to-many relationship
between `x` and `y`.还有基于等值连接的过滤连接(Filtering joins):
- 半连接(
semi_join()):保留在y中有匹配的x中的行。
- 反连接(
anti_join()):保留在y中没有匹配的x中的行。
19.5 非等值连接
到此为止,本章均在谈论等值连接。本节则介绍匹配两行的其他方式。
在等值连接中,x 和 y 的键总是相等的,所以输出中只需要显示一个键列。如果要保留两个键列,可以设置 keep = TRUE。
而使用非等值连接时(例如 x$key >= y$key),x 和 y 的键值不一定相等,所以将两个键列均保留。
以下是四类常用的非等值连接类型:
交叉连接(Cross joins):匹配所有行的组合;
不等连接(Inequality joins):使用
<,<=,>,>=;滚动连接(Rolling joins):输出“在不等中最接近”的那一行;
重叠连接(Overlap joins):匹配区间之间的包含或重叠关系。
- 交叉连接:匹配每一行与另一张表中的所有行,输出笛卡尔积,即
nrow(x) × nrow(y),用于生成所有排列组合。如下,输出结果是所有可能的名字对,包括自配(自己和自己):
df <- tibble(name = c("John", "Simon", "Tracy", "Max"))
df |> cross_join(df)
#> # A tibble: 16 × 2
#> name.x name.y
#> <chr> <chr>
#> 1 John John
#> 2 John Simon
#> ...
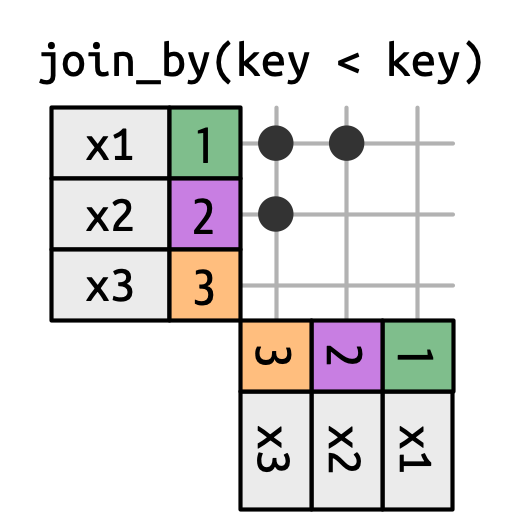
不等连接:使用<,<=,>=,>来限制匹配的行,比如x$key < y$key。
不等连接可以用于限制交叉连接的范围,比如只保留 id 小的组合,即生成组合而非排列:
df <- tibble(id = 1:4, name = c("John", "Simon", "Tracy", "Max"))
df |> inner_join(df, join_by(id < id))
#> # A tibble: 6 × 4
#> id.x name.x id.y name.y
#> <int> <chr> <int> <chr>
#> 1 1 John 2 Simon
#> 2 1 John 3 Tracy
#> ...
- 滚动连接:一种特殊的不等连接,不会返回所有匹配的行,而是只返回最“接近”的一行。
可以使用 closest() 实现滚动匹配:
join_by(closest(x <= y)):找到最小的y,使得y ≥ xjoin_by(closest(x > y)):找到最大的y,使得y < x
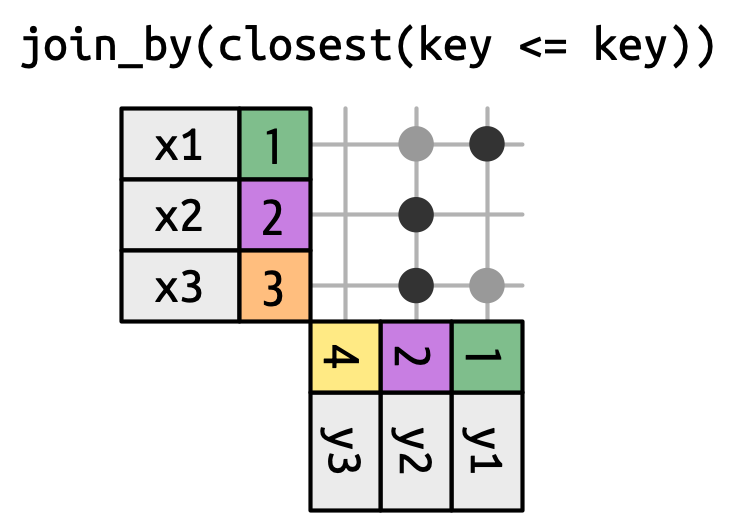
- 重叠连接:可以更明确地处理区间范围匹配,有三个辅助函数:
between(x, y_lower, y_upper)等价于x >= y_lower, x <= y_upper.within(x_lower, x_upper, y_lower, y_upper)等价于x_lower >= y_lower, x_upper <= y_upper.overlaps(x_lower, x_upper, y_lower, y_upper)等价于x_lower <= y_upper, x_upper >= y_lower.