27 Base R 实战指南
27.1 引言
本章介绍 Base R。
本书前面重点介绍 tidyverse,是因为其套件遵循统一的设计理念,整洁优雅。但使用 tidyverse 必然需要 Base R ,比如从加载包的 library(),到数值汇总的 sum() 和 mean(),再到因子(factor)、日期(date)和 POSIXct 数据类型,以及所有基础运算符(如 +, -, /, *, |, &, ! 等)。
而 Base R 的工作流程此前尚未系统讲解,本章将补全这最后一块拼图。
本章以 Base R 为核心,为了对比差异,需加载 tidyverse 作为参照:
library(tidyverse)27.2 使用 [] 选择多个元素
[] 用于从向量和数据框中提取子组件,称为向量子集化。使用形式为 x[i] 或 x[i, j]。某些 dplyr 动词其实是 [] 的特殊形式。
27.2.1 子集化向量
x[i] 中的i有五种常见对象 :
- 正整数向量
使用正整数子集化会保留对应位置的元素:
x <- c("one", "two", "three", "four", "five")
x[c(3, 2, 5)]
#> [1] "three" "two" "five"通过重复,可得到比原来更长的向量,因此“子集化”这个词并不总是字面意义上的“变小”。
x[c(1, 1, 5, 5, 5, 2)]
#> [1] "one" "one" "five" "five" "five" "two"- 负整数向量
使用负整数则会删除指定位置的元素:
x[c(-1, -3, -5)]
#> [1] "two" "four"- 逻辑向量
使用逻辑向量时,仅保留对应 TRUE 的位置:
x <- c(10, 3, NA, 5, 8, 1, NA)
# 所有非缺失值
x[!is.na(x)]
#> [1] 10 3 5 8 1
# 所有偶数及NA
x[x %% 2 == 0]
#> [1] 10 NA 8 NA- 字符向量
如果一个向量有名称,可以用字符向量来进行子集化:
x <- c(abc = 1, def = 2, xyz = 5)
x[c("xyz", "def")]
#> xyz def
#> 5 2- 空值(Nothing)
最后一种子集方式是空 x[],返回完整的 x。
27.2.2 子集化数据框
数据框子集化有很多方法,最重要的是 df[rows, cols],即分别选择行和列。rows 和 cols 可以是前述的任意一种向量类型。
例如:
df <- tibble(
x = 1:3,
y = c("a", "e", "f"),
z = runif(3)
)
# 选择第1行第2列
df[1, 2]
#> # A tibble: 1 × 1
#> y
#> <chr>
#> 1 a
# 选择所有行和列
df[, c("x", "y")]
#> # A tibble: 3 × 2
#> x y
#> <int> <chr>
#> 1 1 a
#> 2 2 e
#> 3 3 f
# 选择 x > 1 的所有行
df[df$x > 1, ]
#> # A tibble: 2 × 3
#> x y z
#> <int> <chr> <dbl>
#> 1 2 e 0.834
#> 2 3 f 0.601
df$x用于提取数据框中名为x的列。此处需要使用$是因为[不支持 tidy evaluation,所以必须显式写出变量来源。
27.2.3 dplyr 的等效写法
很多 dplyr 的动词其实就是 [] 的特殊形式。
filter() 相当于使用逻辑向量筛选行,同时排除缺失值:
df <- tibble(
x = c(2, 3, 1, 1, NA),
y = letters[1:5],
z = runif(5)
)
df |> filter(x > 1)
# 等价于
df[!is.na(df$x) & df$x > 1, ][]中也可使用 which() 来自动去除 NA:
df[which(df$x > 1), ]arrange() 相当于使用整数向量(通常由 order() 创建)对行排序:
df |> arrange(x, y)
# 等价于
df[order(df$x, df$y), ][]中降序排序可以使用 order(..., decreasing = TRUE),或者对某列用 -rank(col)。
select() 和 relocate() 类似于使用字符向量选择列:
df |> select(x, z)
# 等价于
df[, c("x", "z")]Base R 还提供了一个结合了 filter() 和 select() 功能的函数 subset():
df |>
filter(x > 1) |>
select(y, z)
#> # A tibble: 2 × 2
#> y z
#> <chr> <dbl>
#> 1 a 0.157
#> 2 b 0.00740
# 等价于
df |> subset(x > 1, c(y, z))27.3 使用 $ 和 [[]] 选择单个元素
[] 用于选择多个元素,而 [[]] 和 $ 用于提取单个元素。
27.3.1 数据框
[[]] 和 $ 可以用来从数据框中提取列。[[]] 可通过位置或名称访问,$ 则专用于通过名称访问:
tb <- tibble(
x = 1:4,
y = c(10, 4, 1, 21)
)
# 按位置访问
tb[[1]]
#> [1] 1 2 3 4
# 按名称访问
tb[["x"]]
#> [1] 1 2 3 4
tb$x
#> [1] 1 2 3 4它们也可以用来创建新列,是mutate() 的等价写法:
tb$z <- tb$x + tb$y
tb
#> # A tibble: 4 × 3
#> x y z
#> <int> <dbl> <dbl>
#> 1 1 10 11
#> 2 2 4 6
#> 3 3 1 4
#> 4 4 21 25直接使用 $ 对于快速汇总非常方便。例如下面这一例,要找出最大钻石的重量,或者了解 cut 的取值范围,就不必用 summarize():
max(diamonds$carat)
#> [1] 5.01
levels(diamonds$cut)
#> [1] "Fair" "Good" "Very Good" "Premium" "Ideal"dplyr 也提供了 [[]] 和 $ 的等价函数:pull()。pull() 接受变量名称或变量位置作为参数,并返回该列,从而可以将上面的代码改写为管道:
diamonds |> pull(carat) |> max()
#> [1] 5.01
diamonds |> pull(cut) |> levels()
#> [1] "Fair" "Good" "Very Good" "Premium" "Ideal"27.3.2 Tibbles
在使用 $ 时,tibble 与 base 函数data.frame 有一些差异。 data.frame 会匹配变量名的前缀(即“部分匹配”),列不存在时不会报错:
df <- data.frame(x1 = 1)
df$x
#> [1] 1
df$z
#> NULLtibble 则颇为严格,只精确匹配变量名,列不存在时发出警告:
tb <- tibble(x1 = 1)
tb$x
#> Warning: Unknown or uninitialised column: `x`.
#> NULL
tb$z
#> Warning: Unknown or uninitialised column: `z`.
#> NULL27.3.3 列表
[[]] 和 $ 也可用于处理列表,我们须知晓它们与 [] 的区别。
下面用一个名为 l 的列表来说明:
l <- list(
a = 1:3,
b = "a string",
c = pi,
d = list(-1, -5)
)[] 提取的是子列表。无论提取多少元素,结果仍是列表;而[[ 和 $ 提取的是列表的单个元素:
str(l[1])
#> List of 1
#> $ a: int [1:3] 1 2 3
str(l[[1]])
#> int [1:3] 1 2 3
str(l[4])
#> List of 1
#> $ d:List of 2
#> ..$ : num -1
#> ..$ : num -5
str(l[[4]])
#> List of 2
#> $ : num -1
#> $ : num -5为了帮助读者记忆,来看看本书作者给的图例。假设有一个胡椒罐叫 pepper,其中装的是单独包装好的胡椒包。
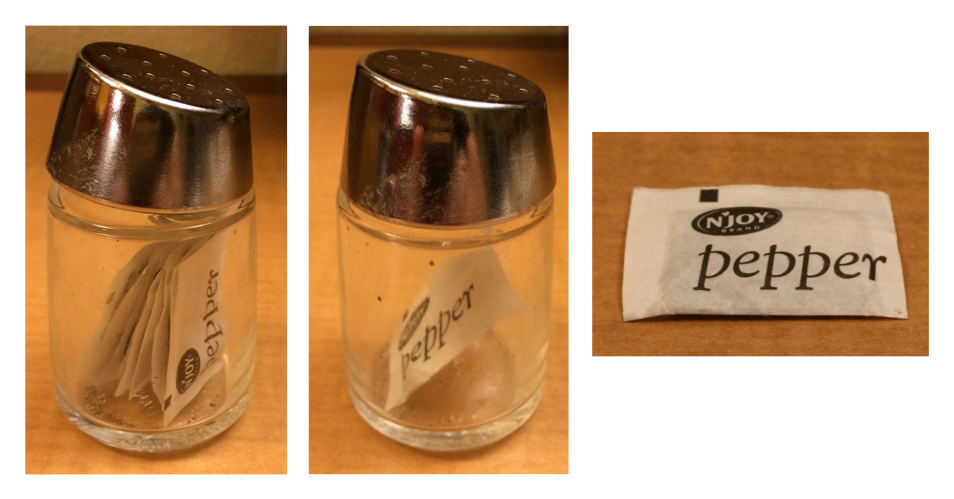
pepper[1]是装着第一个胡椒包的胡椒罐。pepper[2]是装着第二个胡椒包的胡椒罐。pepper[1:2]是装着两个胡椒包的胡椒罐。pepper[[1]]则是直接拿出一个胡椒包,为其本身。
27.4 Apply 家族
apply 家族用于迭代,对应 across() 和 map 系列函数的功能。
lapply()最为常用,与 purrr::map() 非常相似。实际上我们可以把第 26 章中所有的 map() 都换成 lapply()。
虽然 base R 中没有完全等价于 across() 的函数,但通过结合 [] 和 lapply() 可以实现类似效果。因为数据框在底层实际上是由列组成的列表,所以对数据框使用 lapply() 会把函数应用到每一列上。
df <- tibble(a = 1, b = 2, c = "a", d = "b", e = 4)
# 首先找出数值型列
num_cols <- sapply(df, is.numeric)
num_cols
#> a b c d e
#> TRUE TRUE FALSE FALSE TRUE
# 然后用 lapply() 变换每一列,并替换原数据
df[, num_cols] <- lapply(df[, num_cols, drop = FALSE], \(x) x * 2)
df
#> # A tibble: 1 × 5
#> a b c d e
#> <dbl> <dbl> <chr> <chr> <dbl>
#> 1 2 4 a b 8上面的代码还使用了一个新函数 sapply()。它类似于 lapply(),但其结果会对输入进行简化。purrr 中也有类似的函数 map_vec(),但第 26 章中未提及。
此外,还有一个更严格的版本叫 vapply(),即 vector apply。它多了一个参数,用于指定输出模板,从而确保简化结果不受输入影响。例如,可以用 vapply() 来替代上面的 sapply(),明确指定 is.numeric() 返回一个长度为 1 的逻辑向量:
vapply(df, is.numeric, logical(1))
#> a b c d e
#> TRUE TRUE FALSE FALSE TRUE接下来介绍tapply(),用于计算按组汇总的单个值。最常用的形式为tapply(x, group, fun),x是要处理的列,group是用于分组的标准列,fun表示计算方式,比如下面对cut分组,并计算price的均值:
tapply(diamonds$price, diamonds$cut, mean)
#> Fair Good Very Good Premium Ideal
#> 4358.758 3928.864 3981.760 4584.258 3457.542等价的dplyr写法是:
diamonds |>
group_by(cut) |>
summarize(price = mean(price))
#> # A tibble: 5 × 2
#> cut price
#> <ord> <dbl>
#> 1 Fair 4359.
#> 2 Good 3929.
#> 3 Very Good 3982.
#> 4 Premium 4584.
#> 5 Ideal 3458.显然,tapply() 返回的是命名向量,组合成数据框需要额外操作。
最后介绍 apply(),专门用于矩阵和数组,基础用法是apply(x, margin, fun),x是矩阵或数组,margin指定行或列,fun是计算方式。
27.5 for 循环
for 循环是迭代的基础构建模块,是apply 和 map 等函数的底层逻辑。for 循环基本结构如下:
for (element in vector) {
# 一些操作
}for 循环最直接的用途与 walk() 相同,对列表的每个元素调用一个具有副作用的函数。
例如在第 26.4.1 节中使用的 walk():
paths |> walk(append_file)可以用 for 循环来实现同样的功能:
for (path in paths) {
append_file(path)
}如果想保存输出,比如读取一个文件夹下的所有 Excel 文件,用map()操作如下:
paths <- dir("data/gapminder", pattern = "\\.xlsx$", full.names = TRUE)
files <- map(paths, readxl::read_excel)而使用for循环则稍微复杂一些。
首先需要提前明确输出的结构,在此例中,我们的输出应当是与 paths 长度相同的列表,可以用 vector() 来创建:
files <- vector("list", length(paths))
vector基本语法为vector(mode = "logical", length = 0)。model指定向量类型,默认为逻辑向量;length指定向量的初始长度(默认为0)。
接着,我们不直接对 paths 的元素进行迭代,而是对其索引进行迭代,用 seq_along() 为 paths 中的每个元素生成一个索引:
seq_along(paths)
#> [1] 1 2 3 4 5 6 7 8 9 10 11 12使用索引,我们便可以将输入和输出中的位置一一对应起来,完成读取:
for (i in seq_along(paths)) {
files[[i]] <- readxl::read_excel(paths[[i]])
}将包含多个 tibble 的列表合并成一个 tibble,可以用 do.call() + rbind():
do.call(rbind, files)
#> # A tibble: 1,704 × 5
#> country continent lifeExp pop gdpPercap
#> <chr> <chr> <dbl> <dbl> <dbl>
#> 1 Afghanistan Asia 28.8 8425333 779.
#> 2 Albania Europe 55.2 1282697 1601.
#> 3 Algeria Africa 43.1 9279525 2449.
#> 4 Angola Africa 30.0 4232095 3521.
#> 5 Argentina Americas 62.5 17876956 5911.
#> 6 Australia Oceania 69.1 8691212 10040.
#> # ℹ 1,698 more rows比起先建立一个列表再保存结果,更简单的方法是逐步构建数据框:
out <- NULL
for (path in paths) {
out <- rbind(out, readxl::read_excel(path))
}但不推荐这种写法,因为当向量很长时这种方式会非常慢,这也正是“for 循环很慢”这一刻板印象的源头。但实际上,不是 for 循环慢,而是反复扩展向量的过程慢。
27.6 R base 绘图
尽管ggplot2几乎是最有优势的绘图工具,但base R绘图函数仍因其简洁性而具有实用价值,只需极少代码即可完成基础探索性图表。
实际分析中最常见的 base R 图表有两种,分别是散点图plot()和直方图hist()。以下以diamonds数据集为例进行演示:
# 左图:直方图
hist(diamonds$carat)
# 右图:散点图
plot(diamonds$carat, diamonds$price)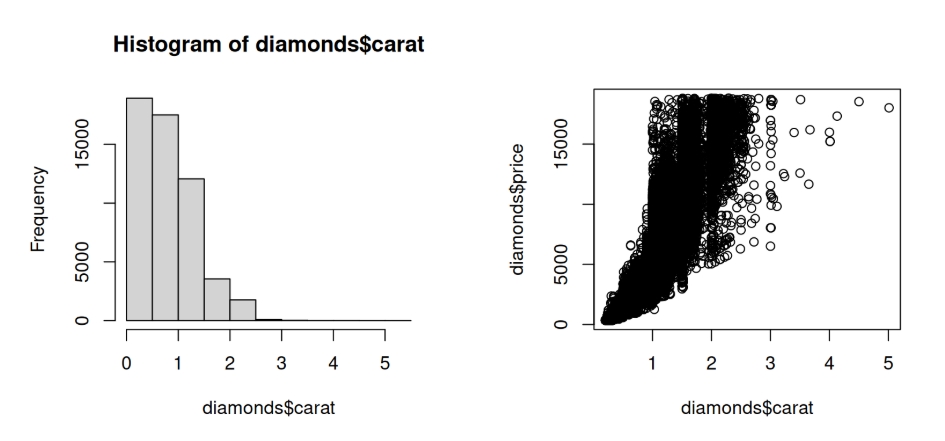
需注意,base R 绘图函数必须直接操作向量,因此需要通过$等方式从数据框中提取列。