# 一段耗时计算的代码28 Quarto
28.1 引言
Quarto 是一个面向数据科学的统一创作框架,支持可完全复现的文档生成,且输出格式多样。
Quarto 是一个命令行工具,而非 R 包,因此无法通过 ? 获取帮助。不过可查阅Quarto 官方文档。
简言之,Quarto 就是进阶版的 R Markdown,它整合了 R Markdown 生态中的多个包(如 rmarkdown、bookdown、distill、xaringan 等),且扩展了对多语言(如 Python、Julia 和 R)的原生支持。
使用 Quarto 需要安装命令行接口(CLI),但在 RStudio 中无须手动安装或加载,系统会在需要时自动完成相关配置。
28.2 Quarto 基础
Quarto 文件包含三种重要的内容类型:
- 可选的 YAML 头部信息,使用
---包围; - R 代码块,用三重反引号(```)包围;
- 普通文本,格式与markdown基本一致,比如
#表示标题,_文本_表示斜体。
下图展示 RStudio 中的 .qmd 文档,可以点击代码块顶部的Run按钮(形似播放键)来运行每个代码块,或按快捷键 Ctrl + Shift + Enter。RStudio 会执行代码并将结果嵌入代码块下方显示。
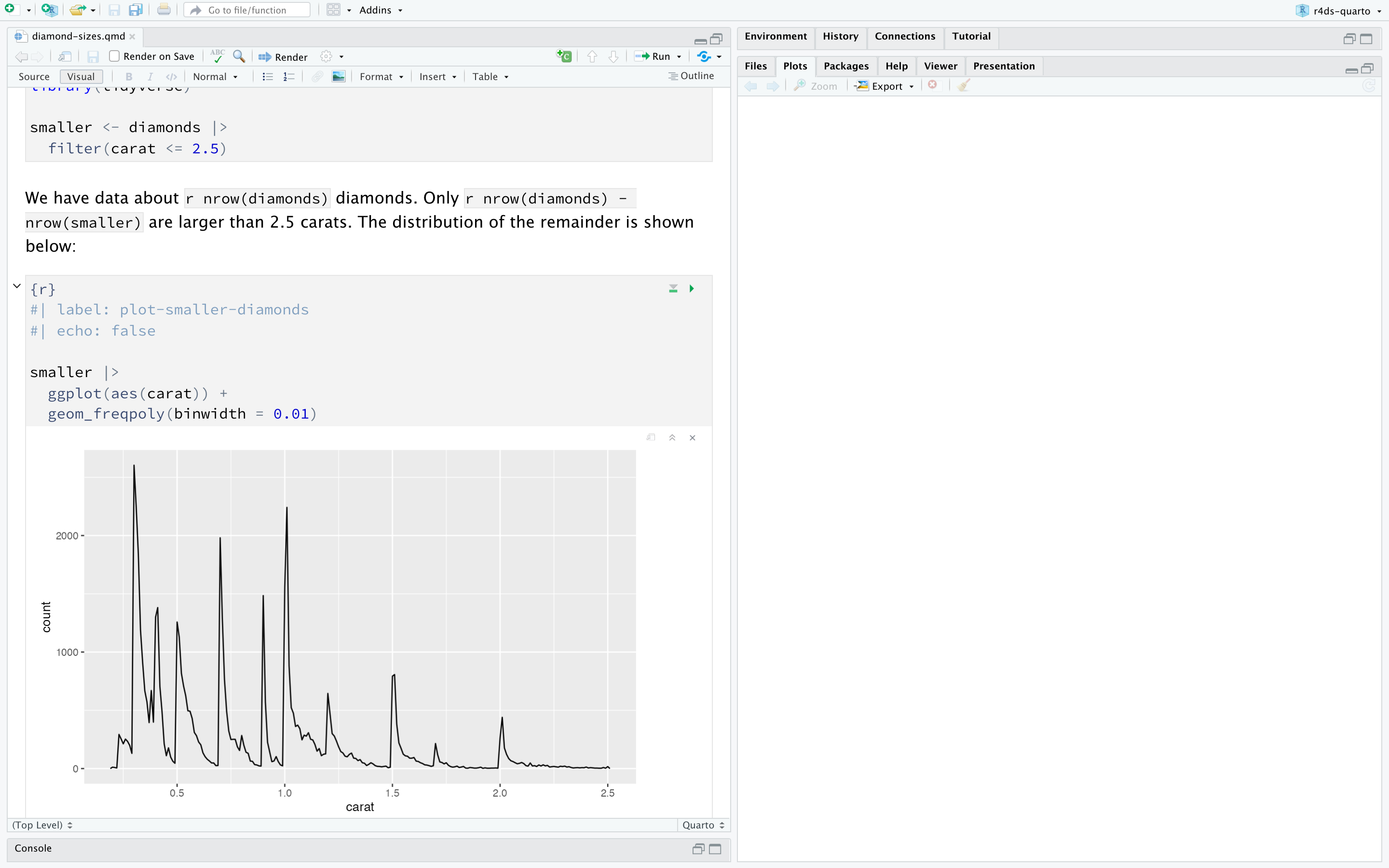
如果不希望在文档中直接看到图表和输出,而想使用 RStudio 的 Console 和 Plots 面板,可以点击Render旁的齿轮图标,切换为“Chunk Output in Console”模式,如下图所示。
要生成包含所有文本、代码和结果的完整报告,可点击Render按钮,或使用快捷键 Ctrl + Shift + K。也可以通过代码方式执行,使报告在 Viewer 面板中显示,同时生成一个 HTML 文件:
quarto::quarto_render("diamond-sizes.qmd")在渲染过程中,Quarto 首先将 .qmd 文件交给 knitr,它会执行所有代码块,并生成包含代码及其输出的 Markdown 文件。随后该 Markdown 文件会由 pandoc 处理,生成最终格式的文件(如 PDF、Word、HTML)。这个流程如下图所示。

通过以下路径即可创建 .qmd 文件: File > New File > Quarto Document…
RStudio 会启动一个向导,帮助我们预先填充一些常用内容,并提示如何使用 Quarto 的核心功能。
28.3 可视化编辑器
在底层,Quarto 文档(.qmd 文件)中的正文使用 Markdown 编写。
在可视化编辑器中,除了使用菜单栏按钮插入图像、表格、引用等,也可使用通用快捷键 ⌘ + /(Mac)或 Ctrl + /(Windows/Linux)插入。如果位于某行开头,只输入 / 也可以触发快捷方式。
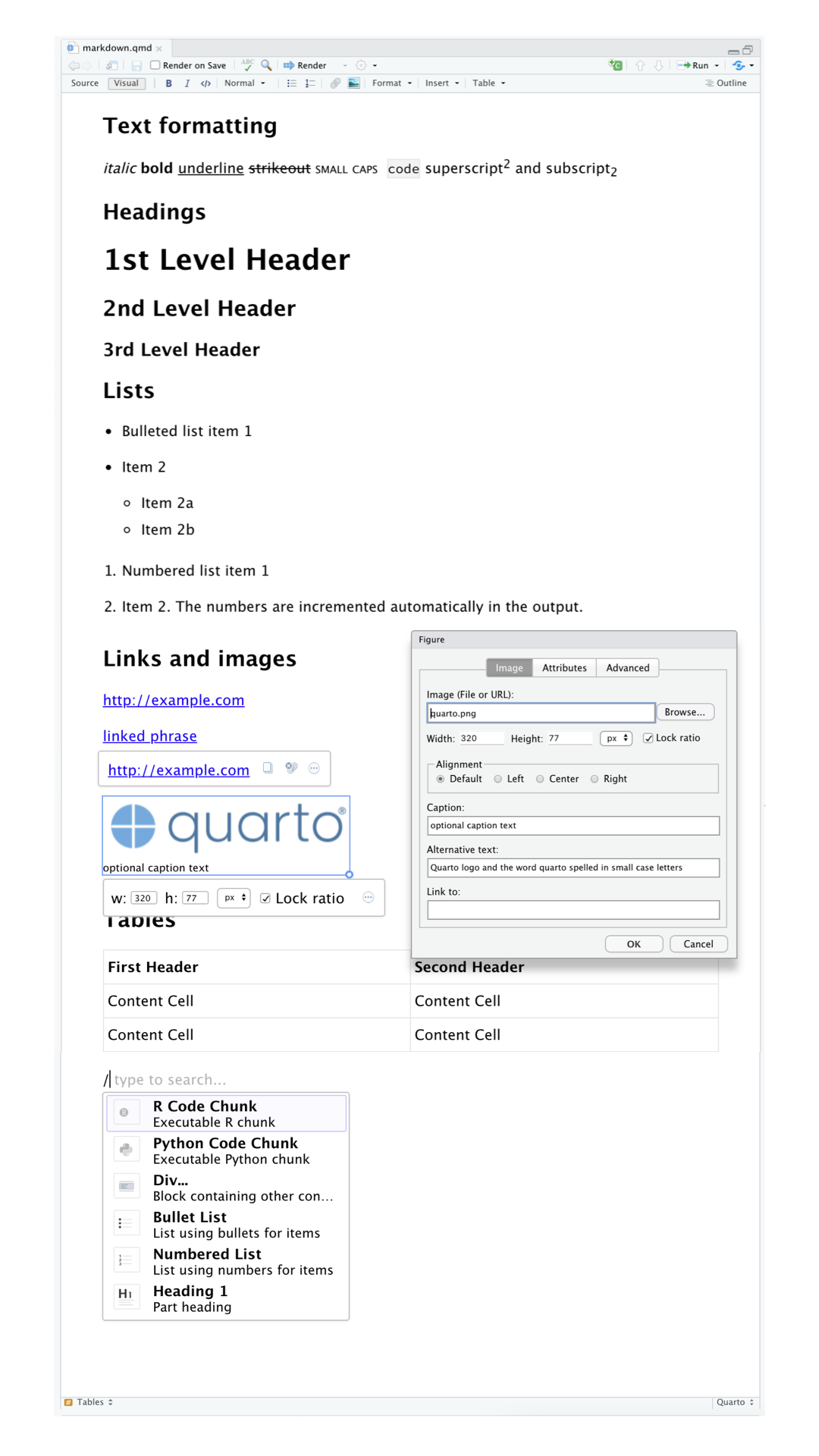
虽然可视化编辑器会以格式化方式展示内容,但底层仍以纯 Markdown 存储。可视化编辑器与源代码编辑器之间能够随时切换,从而方便查看和编辑内容。
28.4 源代码编辑器
使用源代码编辑器编辑 Quarto 文档需要掌握markdown语法,下面简单展示部分格式。
## Text formatting
*italic* **bold** ~~strikeout~~ `code`
superscript^2^ subscript~2~
[underline]{.underline} [small caps]{.smallcaps}
## Headings
# 1st Level Header
## 2nd Level Header
### 3rd Level Header
## Lists
- Bulleted list item 1
- Item 2
- Item 2a
- Item 2b
1. Numbered list item 1
2. Item 2.
The numbers are incremented automatically in the output.
## Links and images
<http://example.com>
[linked phrase](http://example.com)
{fig-alt="Quarto logo and the word quarto spelled in small case letters"}
## Tables
| First Header | Second Header |
|--------------|---------------|
| Content Cell | Content Cell |
| Content Cell | Content Cell |28.5 代码块
在 Quarto 文档中插入一个代码块可以通过以下三种方式完成:
- 使用快捷键:Cmd + Option + I(Mac) / Ctrl + Alt + I(Windows/Linux)
- 点击编辑器工具栏中的 “Insert” 按钮图标
- 手动输入代码块分隔符,比如```{r}
代码块本身还有一个新快捷键:Cmd/Ctrl + Shift + Enter,可一次运行整个代码块。
以下小节介绍代码块的头部结构:以 ```{r} 开始,后续添加代码块标签和多个块选项,每项单独占一行,前缀为 #|。
28.5.1 块标签
代码块可以指定一个可选的标签,例如:
```{r}
#| label: simple-addition
1 + 1
```输出:
#> [1] 2标签有三个好处:
- 能通过 RStudio 编辑器左下角的代码导航器快速跳转至特定块。
- 便于后续引用。
- 可构建缓存依赖关系。
标签应简短且具描述性,不能含空格,建议使用连字符 - 分隔单词(不推荐使用下划线 _)。
有一个特殊标签setup。当处于笔记本模式时,名为 setup 的代码块将在其它代码运行前被自动执行。
此外,块标签必须唯一,不可重复。
28.5.2 块选项
可通过在代码块开头指定选项,对代码块输出进行控制。knitr 提供了近 60 个选项,可参考完整列表:https://yihui.org/knitr/options。
以下是最常用的一些选项:
eval: false—— 不运行代码。适用于展示示例代码,或临时屏蔽一大段代码而不逐行注释。include: false—— 运行代码,但不显示代码和结果。适合用于初始化设置代码。echo: false—— 不显示代码,但保留结果。适用于隐藏底层 R 代码。message: false/warning: false—— 不显示消息或警告信息。results: hide—— 隐藏文本输出;fig-show: hide—— 隐藏图形输出。error: true—— 即使代码报错也继续渲染。
这些选项以 #| 前缀写在代码块头部,例如:
```{r}
#| label: simple-multiplication
#| eval: false
2 * 2
```28.5.3 全局选项
随着 knitr 使用的深入,可能默认的块选项不再符合需求,那么就需要在文档层面进行全局设置。在 YAML 区域中通过 execute: 字段设置默认块选项。
例如,想要不显示代码,只展示结果,可以设置:
title: "My report"
execute:
echo: false由于 Quarto 是多语言设计,并非所有 knitr 选项都可放在 execute 下(部分选项仅适用于 knitr,不适用于其他执行引擎如 Jupyter)。但可以使用 knitr和opts_chunk 设置 knitr 专属的全局选项。
例如要将注释符设置为 #>,并将代码与输出紧密排列,可设置:
title: "Tutorial"
knitr:
opts_chunk:
comment: "#>"
collapse: true28.5.4 内联代码
除了代码块,还可使用内联语法将 R 代码嵌入 Quarto 文本中。
28.6 图形
Quarto 文档中的图形可以直接嵌入,也可以由代码块生成。
要从外部文件嵌入图像,可以在 RStudio 的可视化编辑器中使用 “Insert” 菜单并选择 Figure / Image。
Quarto 中主要有五个选项用于调节图形尺寸:
fig-widthfig-heightfig-aspout-widthout-height
图像尺寸调整比较复杂,因为图像有两个尺寸:R 生成图形的实际大小,以及输出文档中显示的大小。
下面通过各种需求来介绍选项。
图形保持一致的宽度会更美观,故而可以在默认设置中设定:
fig-width: 6 # 图形宽度 6 英寸
fig-asp: 0.618 # 黄金比例 用 out-width 控制图形的输出宽度,建议设为输出文档正文宽度的一个百分比,比如:
out-width: "70%"
fig-align: center如果要在一行中放多个图形,可以使用 layout-ncol 设置为 2(两图并排)、3(三图并排)等等。这相当于自动为每张图设置了 out-width 为 50%、33% 等。
如果图中文字太小,则调整 fig-width,且通常需要通过试错来确定最佳宽高比。
若要在文字中穿插代码和图形,你可以使用 fig-show: hold,从而能让图形在代码之后展示。
要为图添加标题,可以使用 fig-cap。添加标题后,图像会变成“浮动图形”(可编号、可引用)。
28.7 表格
生成表格同样有两种方式。一种是直接通过 “Insert Table” 菜单插入的 Markdown 表格;另一种是由代码块生成表格。
默认情况下,Quarto 会以类似控制台输出的形式打印数据框和矩阵:
mtcars[1:5, ]
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
#> Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
#> Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
#> Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
#> Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2如果希望数据的展示方式更有条理,可以使用 knitr::kable() 函数。例如此代码会生成下面的表格:
knitr::kable(mtcars[1:5, ])| mpg | cyl | disp | hp | drat | wt | qsec | vs | am | gear | carb | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Mazda RX4 | 21.0 | 6 | 160 | 110 | 3.90 | 2.620 | 16.46 | 0 | 1 | 4 | 4 |
| Mazda RX4 Wag | 21.0 | 6 | 160 | 110 | 3.90 | 2.875 | 17.02 | 0 | 1 | 4 | 4 |
| Datsun 710 | 22.8 | 4 | 108 | 93 | 3.85 | 2.320 | 18.61 | 1 | 1 | 4 | 1 |
| Hornet 4 Drive | 21.4 | 6 | 258 | 110 | 3.08 | 3.215 | 19.44 | 1 | 0 | 3 | 1 |
| Hornet Sportabout | 18.7 | 8 | 360 | 175 | 3.15 | 3.440 | 17.02 | 0 | 0 | 3 | 2 |
28.8 缓存
一般来说,每次渲染文档时都会从一个完全干净的环境重新开始。这从可重复性的角度出发固然很好,能确保所有重要的计算都写已进代码。然而,如果一些计算耗时特别长,再次渲染会很痛苦。
解决方案是设置 cache: true,从文档层次(也就是全局)缓存所有计算的结果:
---
title: "My Document"
execute:
cache: true
---也可以在代码块级别启用缓存,仅缓存某个特定代码块中的计算结果:
不过,默认情况下缓存只基于代码自身,不包含依赖项。例如以下代码中,processed_data 代码块依赖于 raw-data 代码块:
```{r}
#| label: raw-data
#| cache: true
rawdata <- readr::read_csv("a_very_large_file.csv")
```{{r}}
#| label: processed_data
#| cache: true
processed_data <- rawdata |>
filter(!is.na(import_var)) |>
mutate(new_variable = complicated_transformation(x, y, z))
```此时若缓存作为附属的 processed_data ,则意味着如果 raw-data 的调用发生变化,它并不会重新运行。可以使用 dependson 选项来避免这个问题,该选项应包含一个字符向量,列出该缓存块依赖的所有代码块。knitr 检测到被依赖代码发生变化时,会更新缓存块的结果。
```{r}
#| label: processed-data
#| cache: true
#| dependson: "raw-data"
processed_data <- rawdata |>
filter(!is.na(import_var)) |>
mutate(new_variable = complicated_transformation(x, y, z))
```若要让缓存随着外部文件的变化而更新,可以使用 cache.extra 。该选项接受任意 R 表达式,只要其结果变化,缓存就会失效。
另外还有一个实用函数file.mtime(),它会返回文件的最后修改时间。例如:
```{{r}}
#| label: raw-data
#| cache: true
#| cache.extra: !expr file.mtime("a_very_large_file.csv")
rawdata <- readr::read_csv("a_very_large_file.csv")
```建议定期清理所有缓存,使用:
knitr::clean_cache()28.9 修bug
Quarto 文档并非交互式环境,调试过程可能不太直观。但究其错误根源,主要分为文档结构问题与内嵌代码问题两类。
一个典型的结构性错误是代码块标签重复,极易发生在复制粘贴时。解决方法:检查报错信息或文档源码,找到重复的标签名,手动将其修改为全局唯一的名称,例如将重复的 unnamed-chunk-1 分别改为 data-loading 和 plot-generation。
当错误由 R 代码本身引起时,核心的排查思路是在交互式环境中复现问题。方法:首先重启 R 会话,创造一个干净的环境,然后运行 Ctrl + Alt + R 执行文档中的所有代码块。一旦成功复现,就可以像处理普通 R 脚本一样,使用 print()、browser() 或调试器进行逐行交互式诊断。
如果无法在交互环境中复现,则证明两者环境存在差异,必须进行系统排查。系统性解决方法:首先,通过包含 getwd() 的代码块确认 Quarto 的工作目录,并在交互会话中通过 setwd() 切换到相同路径。其次,在问题代码块顶部设置 error: true,确保渲染不会因报错而中断;然后,在代码块内部关键步骤后,插入 str()、print() 或 ls() 等语句,将变量内容、数据结构乃至当前环境中的所有对象名称打印输出,通过对比两份输出结果,即可发现隐藏的变量差异或依赖缺失。
28.10 YAML
Quarto 使用 YAML 调整输出的细节。
28.10.1 自包含
HTML 文档通常依赖诸多外部资源(例如图片、CSS 样式表、JavaScript 等),默认情况下这些文件会被放在与 .qmd 文件同目录下的 _files 文件夹中,并非自包含。
若要将报告通过电子邮件发送出去,便常常需要自包含的 HTML 文件,其中嵌入所有依赖文件。可以如下设置:
format:
html:
embed-resources: true生成的文件是自包含的,在浏览器中显示时不需要任何外部文件或网络连接。
28.11 参数
Quarto 文档中可以包含一个或多个动态参数,格式为:
在YAML中使用 params 字段对参数进行指定。例如,下面这个例子使用参数 my_class 来决定要展示哪一类汽车:
---
format: html
params:
my_class: "suv"
---另外也可以通过 !expr 来动态执行任意 R 表达式。例如用于设置日期/时间参数:
params:
start: !expr lubridate::ymd("2015-01-01")
snapshot: !expr lubridate::ymd_hms("2015-01-01 12:30:00")28.12 参考文献与引用
要使用可视化编辑器添加引用,选择Insert > Citation。可以从多种来源插入引用:
- DOI(文献数字对象唯一标识符)
- Zotero 个人或团队图书馆
- Crossref、DataCite 或 PubMed 的搜索结果
- 本地
.bib文献数据库文件
在源码编辑器中,使用引用标识符进行引用。其格式为 '@' + 文献条目ID,再放到方括号中。例如:
多个引用用分号分隔
Blah blah [@smith04; @doe99].
可以在方括号内添加任意注释
Blah blah [see @doe99, pp. 33-35; also @smith04, ch. 1].
去掉方括号以创建正文引用
@smith04 says blah, or @smith04 [p. 33] says blah.
在引用前加 `-` 省略作者名
Smith says blah [-@smith04].在渲染文档时,Quarto 会构建参考文献并附加到文档末尾,但不会自动添加章节标题,因此要手动添加。
28.13 工作流程
Quarto 的一大优势是紧密整合了代码与文本,既可开发代码,又能记录思路。
Quarto的记录应追求三大目标:
- 追溯完整过程。系统性地记录每个操作步骤及其背后的决策逻辑,能够确保重要信息不会遗失。
- 显性思考。实时记录分析思路和反思过程,形成严谨的分析逻辑链。从而提升最终报告的质量,减少后期文档整理的工作量。
- 团队协作。数据分析本质上是协作性工作,记录信息利于团队知识传递及后续工作延续。
作者对于工作记录的方法论如下:
给记录文件取一个有描述性且易懂的文件名,且开头一段应当简要说明分析目的。
使用 YAML 头部的
date字段记录你开始工作的日期时,使用 ISO8601 格式(YYYY-MM-DD),避免歧义:date: 2016-08-23如果在某个分析思路上投入了大量时间,但最终发现是死胡同,也不要删除!以后重新回顾这个分析时,它可以作为前车之鉴。
最好在 R 之外进行数据录入。若不得不记录少量数据,应使用
tibble::tribble()明确列出。如果发现数据文件中有错误,绝不直接修改原始文件, 而应该写代码去修正该值,并添加注释。
结束每天的工作前,执行完整渲染验证文档可运行性,同时记得清除缓存。
如果希望代码在未来依然可复现(比如一年后能再次运行),就需要追踪代码使用的包的版本。可使用 renv 将包保存在项目目录中。也可以代码块中运行
sessionInfo(),便能知道当前使用了哪些包。建议将自己的每个笔记本放在独立的项目中,并制定标准化命名方案。