23 层次化数据
23.1 引言
本章将学习数据矩形化(data rectangling)技术:将具有层次结构或树状结构的数据转换为由行和列组成的矩形数据框。这项技术在当下数据科学的大环境显得尤为重要,因为层次化数据在实际应用中极为常见,特别是用于处理网络数据。
本章将使用以下工具:
- tidyr(tidyverse核心成员)
- repurrrsive(提供矩形化练习数据集)
- jsonlite(将JSON文件读取为R列表)
加载所需包:
library(tidyverse)
library(repurrrsive)
library(jsonlite)23.2 列表
到目前为止,我们已经使用过包含简单向量的数据框,例如整数、数值、字符、日期时间和因子。这些向量之所以简单,是因为它们是同质的,即每个元素的数据类型相同。如果想在同一个向量中存储不同类型的元素,就需要使用列表(list),可以通过list()创建:
x1 <- list(1:4, "a", TRUE)
x1
#> [[1]]
#> [1] 1 2 3 4
#>
#> [[2]]
#> [1] "a"
#>
#> [[3]]
#> [1] TRUE列表的组件命名很方便,方法与命名 tibble 的列类似:
x2 <- list(a = 1:2, b = 1:3, c = 1:4)
x2
#> $a
#> [1] 1 2
#>
#> $b
#> [1] 1 2 3
#>
#> $c
#> [1] 1 2 3 4即使是这些非常简单的列表,直接打印也会占用大量空间。str()是一种高效的显示方式,它会生成一个紧凑的结构,弱化具体内容,省时省空间:
str(x1)
#> List of 3
#> $ : int [1:4] 1 2 3 4
#> $ : chr "a"
#> $ : logi TRUE
str(x2)
#> List of 3
#> $ a: int [1:2] 1 2
#> $ b: int [1:3] 1 2 3
#> $ c: int [1:4] 1 2 3 4可以看到,str()将列表的每个子元素单独显示在一行中。如果存在名称,它会先显示名称,然后是类型的缩写,接着是前几个值。
列表可以包含任何类型的对象,包括其他列表。这一特性使其利于表示层级(树状)结构:
x4 <- list(1, list(2, list(3, list(4, list(5)))))
str(x4)
#> List of 2
#> $ : num 1
#> $ :List of 2
#> ..$ : num 2
#> ..$ :List of 2
#> .. ..$ : num 3
#> .. ..$ :List of 2
#> .. .. ..$ : num 4
#> .. .. ..$ :List of 1
#> .. .. .. ..$ : num 5注意到随着列表变得复杂,
str()的优势更加明显,层级结构一目了然。
这与创建向量的函数c()有显著差异,c()只会生成一个扁平向量:
c(c(1, 2), c(3, 4))
#> [1] 1 2 3 4
x4 <- c(list(1, 2), list(3, 4))
str(x5)
#> List of 4
#> $ : num 1
#> $ : num 2
#> $ : num 3
#> $ : num 4当列表变得更大更复杂时,str()最终会失效,此时需要用到View(),会显示出可交互的查看页面。下图是调用View(x4)的结果。
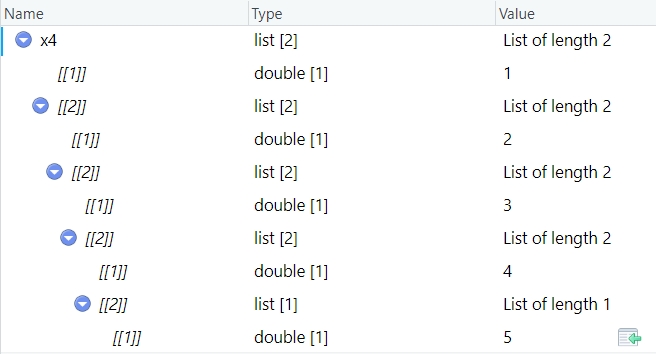
列表也可以存在于 tibble 中,称为列表列(list-columns)。
以下是一个简单的列表列示例:
df <- tibble(
x = 1:2,
y = c("a", "b"),
z = list(list(1, 2), list(3, 4, 5))
)
df
#> # A tibble: 2 × 3
#> x y z
#> <int> <chr> <list>
#> 1 1 a <list [2]>
#> 2 2 b <list [3]>tibble 中的列表没有什么特别之处,其操作与任何其他类型一样:
df |>
filter(x == 1)
#> # A tibble: 1 × 3
#> x y z
#> <int> <chr> <list>
#> 1 1 a <list [2]>如果想查看,需要单独提取该列表列并应用上述方法之一,例如下面两种方式:
df |> pull(z) |> str()
df |> pull(z) |> View()在 base R 中,也可以将列表放入数据框的列中,但操作更繁琐,因为如果直接使用data.frame(),则会按列直接分别列出整个列表,而非将每个列表作为一个整体元素:
data.frame(x = list(1:3, 3:5))
#> x.1.3 x.3.5
#> 1 1 3
#> 2 2 4
#> 3 3 5可以通过将列表包装在I()中,强制data.frame()将其视为行的列表,但打印效果不佳:
data.frame(
x = I(list(1:2, 3:5)),
y = c("1, 2", "3, 4, 5")
)
#> x y
#> 1 1, 2 1, 2
#> 2 3, 4, 5 3, 4, 523.3 解除嵌套
如何将列表和列表列转换回常规的行和列?
列表列通常有两种基本形式:命名的和未命名的。
- 被命名的子元素通常在各行中具有相同的名称。例如在df1中,列表列y的每个元素都有两个名为a和b的子元素。
df1 <- tribble(
~x, ~y,
1, list(a = 11, b = 12),
2, list(a = 21, b = 22),
3, list(a = 31, b = 32),
)命名的列表列解除嵌套后,每个命名元素都会成为一个新的命名列。
针对此情况,使用unnest_wider()函数将各元素按名称拆开分列,如下所示:
df1 |>
unnest_wider(y)
#> # A tibble: 3 × 3
#> x a b
#> <dbl> <dbl> <dbl>
#> 1 1 11 12
#> 2 2 21 22
#> 3 3 31 32默认情况下,列表元素的名称即为新列的名称。可以使用names_sep参数将列名和元素名进行组合,得到更具特征性的列名。
df1 |>
unnest_wider(y, names_sep = "_")
#> # A tibble: 3 × 3
#> x y_a y_b
#> <dbl> <dbl> <dbl>
#> 1 1 11 12
#> 2 2 21 22
#> 3 3 31 32- 若子元素未被命名,元素数量通常在不同行间会有所变化。例如在df2中,列表列y的元素未被命名且长度从一到三不等。
df2 <- tribble(
~x, ~y,
1, list(11, 12, 13),
2, list(21),
3, list(31, 32),
)未命名的列表列解除嵌套后,每个子元素都会单独生成一行。
针对此情况,使用unnest_longer()进行拆分:
df2 |>
unnest_longer(y)
#> # A tibble: 6 × 2
#> x y
#> <dbl> <dbl>
#> 1 1 11
#> 2 1 12
#> 3 1 13
#> 4 2 21
#> 5 3 31
#> 6 3 32如果列表列的其中一个列没有元素,则该行不显式输出。
df6 <- tribble(
~x, ~y,
"a", list(1, 2),
"b", list(3),
"c", list()
)
df6 |> unnest_longer(y)
#> # A tibble: 3 × 2
#> x y
#> <chr> <dbl>
#> 1 a 1
#> 2 a 2
#> 3 b 3如果想保留该行,也就是在y中保留NA,则需设置参数
keep_empty = TRUE。
我们知道,数据框各列所含元素必然类型相同。以上讨论的列表列中的列表,所含元素类型均相同,所以很容易实现元素类型相同的准则。那么如果原列表列类型不统一,拆分后又会如何显示呢?
以下面的数据框df4为例,列表列y共包含两个数字、一个字符和一个逻辑值:
df4 <- tribble(
~x, ~y,
"a", list(1),
"b", list("a", TRUE, 5)
)前面谈过的unnest_longer()函数可以保持列数不变,而行数会变化。针对df4使用该函数效果如下:
df4 |>
unnest_longer(y)
#> # A tibble: 4 × 2
#> x y
#> <chr> <list>
#> 1 a <dbl [1]>
#> 2 b <chr [1]>
#> 3 b <lgl [1]>
#> 4 b <dbl [1]>可见输出包含一个列表列,且每个列表包含单个元素。由于unnest_longer()找不到向量的共同类型,故而仅将元素的原始类型保留在列中。