16 因子
16.1 引言
因子用于表示分类变量,即具有固定且已知取值范围的变量。
forcats从属于tidyverse,是专为分类变量设计的R包,提供了多种因子操作辅助函数。
library(tidyverse)16.2 因子基础
假设存在一个记录月份的变量x1:
x1 <- c("Dec", "Apr", "Jan", "Mar")用字符串记录这个变量存在两个问题:
月份的取值本应限制在 12 个固定值内,但并不会提示可能存在的拼写错误。
字符串排序方式不符合月份实际顺序。
可以通过因子修正这两个问题。首先定义合法取值(即因子水平):
month_levels <- c(
"Jan", "Feb", "Mar", "Apr", "May", "Jun",
"Jul", "Aug", "Sep", "Oct", "Nov", "Dec"
)然后创建因子:
y1 <- factor(x1, levels = month_levels)
y1
#> [1] Dec Apr Jan Mar
#> Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec
sort(y1)
#> [1] Jan Mar Apr Dec
#> Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec所有不在指定水平中的值都会自动转换为 NA:
y2 <- factor(x2, levels = month_levels)
y2
#> [1] Dec Apr <NA> Mar
#> Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec为避免静默失败,可使用 forcats::fct() 这一强校验函数,防止因粗心导致数据缺失而不自知:
y2 <- fct(x2, levels = month_levels)
#> Error in `fct()`:
#> ! All values of `x` must appear in `levels` or `na`
#> ℹ Missing level: "Jam"如果省略 levels 参数,因子水平将按照数据中的字母顺序确定:
factor(x1)
#> [1] Dec Apr Jan Mar
#> Levels: Apr Dec Jan Mar按字母顺序排序存在一定风险,不同计算机可能会以不同方式对字符串排序。因此,forcats::fct() 默认按首次出现顺序排序:
fct(x1)
#> [1] Dec Apr Jan Mar
#> Levels: Dec Apr Jan Mar如果需要直接访问一个因子的水平集合,可以使用 levels():
levels(y2)
#> [1] "Jan" "Feb" "Mar" "Apr" "May" "Jun" "Jul" "Aug" "Sep" "Oct" "Nov" "Dec"在用 readr 读取数据时,可以直接用 col_factor() 创建因子列:
csv <- "
month,value
Jan,12
Feb,56
Mar,12"
df <- read_csv(csv, col_types = cols(month = col_factor(month_levels)))
df$month
#> [1] Jan Feb Mar
#> Levels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec16.3 综合社会调查数据处理
在本章余下的部分,我们将使用 forcats::gss_cat 数据集。它是美国综合社会调查(General Social Survey, GSS)的一部分样本数据,用于展示在处理因子时会遇到的一些常见问题。
gss_cat
#> # A tibble: 21,483 × 9当因子存储在 tibble 中时,其水平不易直接查看。可以通过 count() 函数查看各水平的出现频数:
gss_cat |>
count(race)
#> # A tibble: 3 × 2
#> race n
#> <fct> <int>
#> 1 Other 1959
#> 2 Black 3129
#> 3 White 16395在处理因子时,最常见的两类操作是:
- 更改因子水平的顺序
- 修改因子水平的值
16.4 修改因子顺序
因子水平的顺序通常对可视化效果有影响。例如,要研究不同宗教群体每天平均看电视的小时数:
relig_summary <- gss_cat |>
group_by(relig) |>
summarize(
tvhours = mean(tvhours, na.rm = TRUE),
n = n()
)
ggplot(relig_summary, aes(x = tvhours, y = relig)) +
geom_point()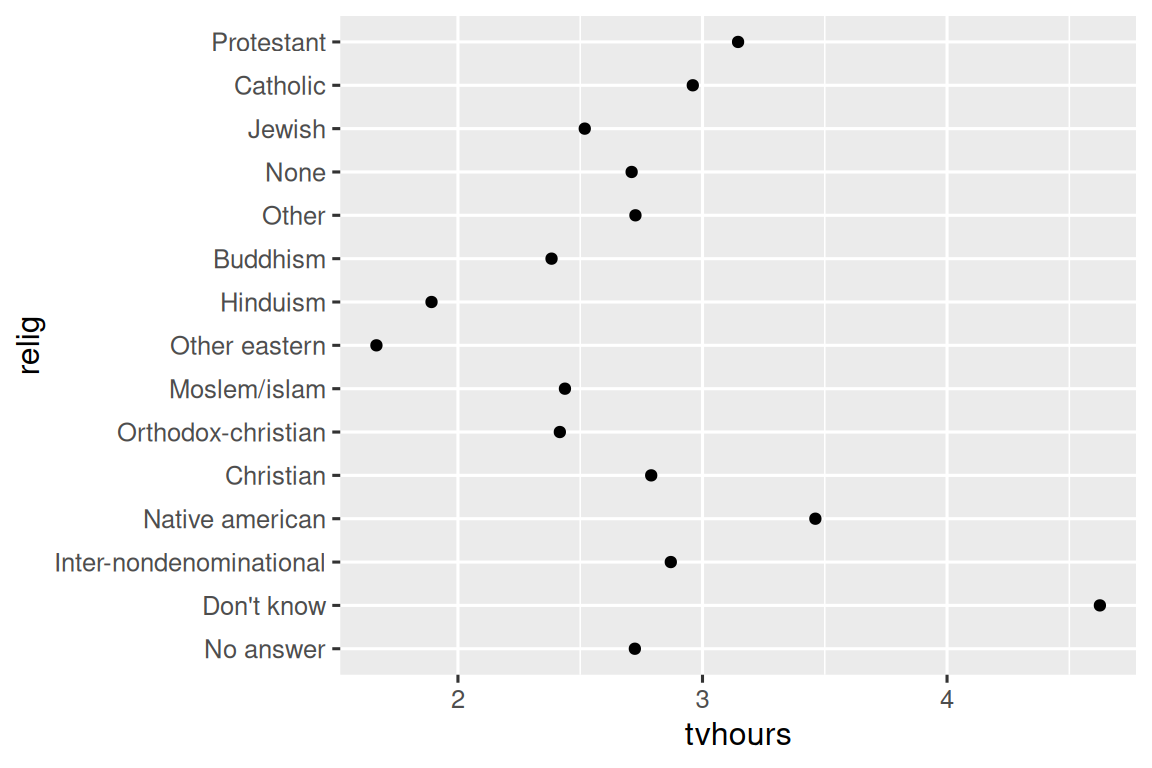
上述散点图中,x 轴是电视观看时长,y 轴是宗教类别。然而,由于 y 轴的顺序是任意设置的,图表很难展示出清晰的整体趋势。
可以用 fct_reorder() 来重新排序水平,使图表更易读。fct_reorder() 有三个参数:
.f:要重新排序的因子;.x:用于排序的数值变量;.fun(可选):如果每个.f有多个.x值,用哪个函数聚合(默认是median)。
ggplot(relig_summary, aes(x = tvhours, y = fct_reorder(relig, tvhours))) +
geom_point()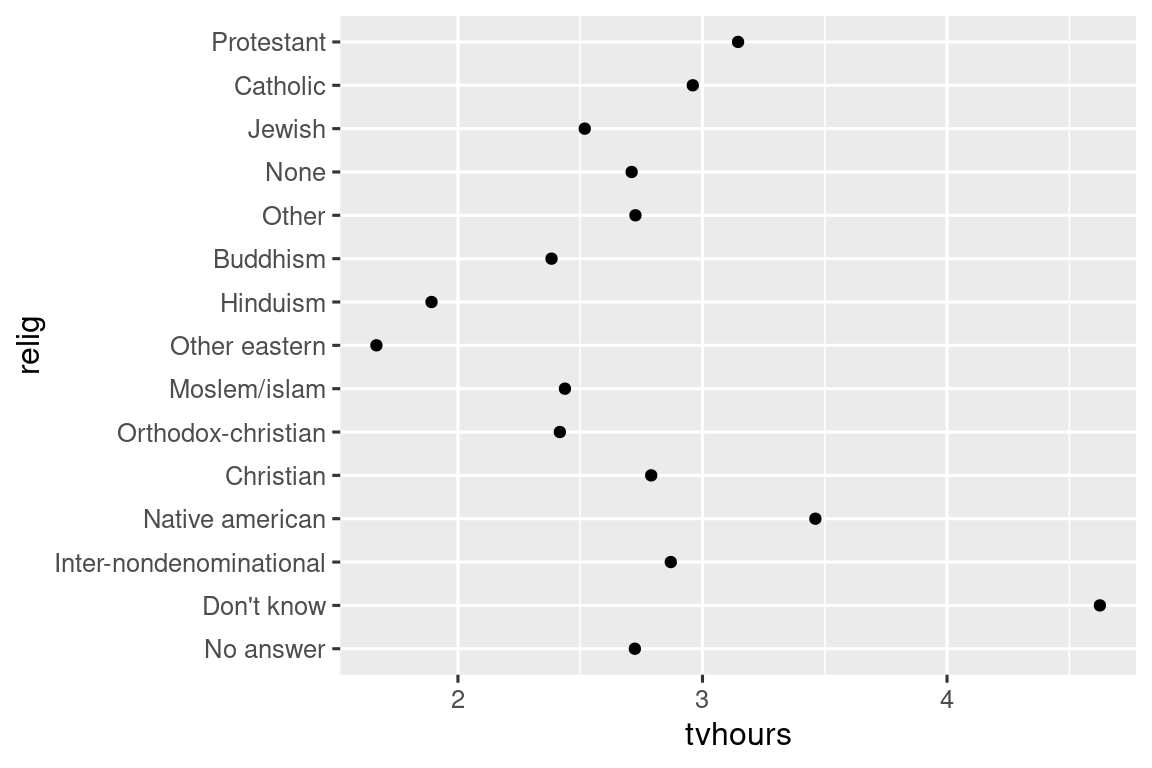
如此一来,宗教类别会按平均电视时长升序排列。可以更容易看出 “Don’t know” 这类人群电视观看时间最多,而 Hinduism 和 Other Eastern 最少。
当变换变得更复杂时,建议将 fct_reorder() 从 aes() 移出,放进一个单独的 mutate() 中,例如:
relig_summary |>
mutate(relig = fct_reorder(relig, tvhours)) |>
ggplot(aes(x = tvhours, y = relig)) +
geom_point()下面用类似的方式研究不同收入水平的平均年龄:
rincome_summary <- gss_cat |>
group_by(rincome) |>
summarize(
age = mean(age, na.rm = TRUE),
n = n()
)
ggplot(rincome_summary, aes(x = age, y = fct_reorder(rincome, age))) +
geom_point()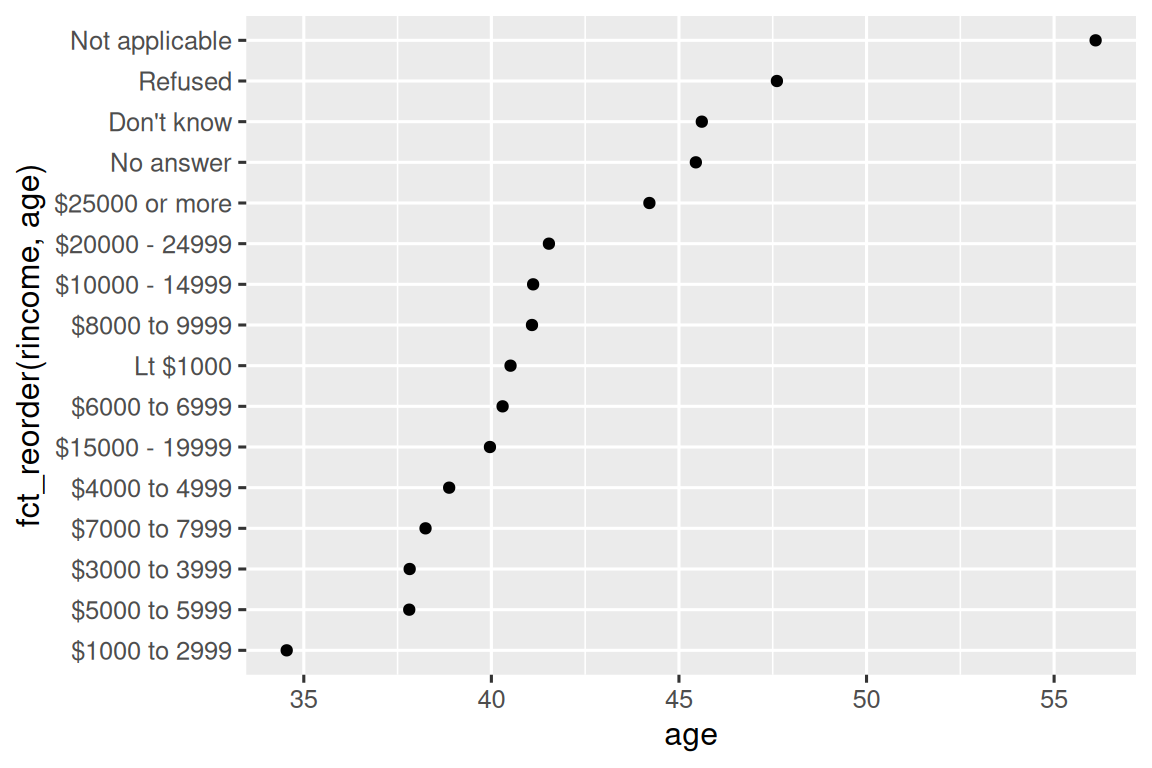
显然,在这个图中重新排序收入水平反而让图表变得更难理解。例如,y 轴上出现了 “$6000–6999” → “<$1000” → “$8000–9999” 的混乱顺序。
这是因为 rincome 已有明确的层级结构,不应该随意打乱。fct_reorder() 更适用于本身没有逻辑顺序的因子。
如果只是想把 “Not applicable” 提到前面和其他特殊项放在一起,可以用 fct_relevel()就行了:
ggplot(rincome_summary, aes(x = age, y = fct_relevel(rincome, "Not applicable"))) +
geom_point()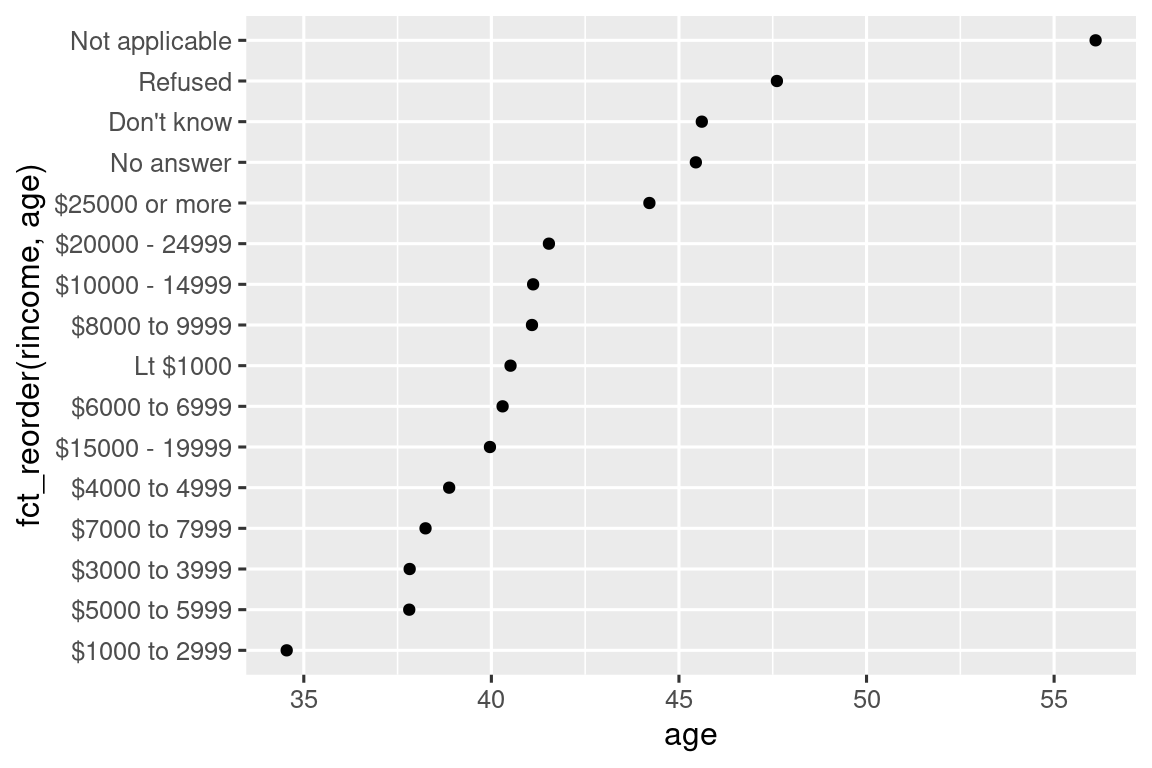
要对线图中的颜色图例排序,可使用fct_reorder2()函数。
fct_reorder2(.f, .x, .y) 按照 .x 最大值对应的 .y 值针对 .f 进行排序,使得图例顺序和图中最右边线条的顺序一致,更易于阅读。
by_age <- gss_cat |>
filter(!is.na(age)) |>
count(age, marital) |>
group_by(age) |>
mutate(prop = n / sum(n))
# 重排前图例
ggplot(by_age, aes(x = age, y = prop, color = marital)) +
geom_line(linewidth = 1) +
scale_color_brewer(palette = "Set1")
# 改善图例顺序
ggplot(by_age, aes(x = age, y = prop, color = fct_reorder2(marital, age, prop))) +
geom_line(linewidth = 1) +
scale_color_brewer(palette = "Set1") +
labs(color = "marital")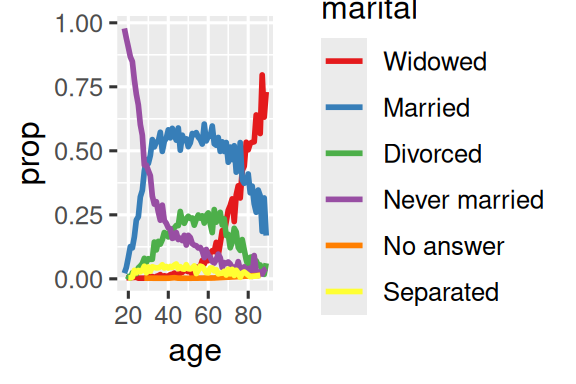
对于柱状图,可以使用 fct_infreq() 按出现频率对因子水平降序排序,这是一种无需额外变量的简单排序方式。如要升序排列,可结合 fct_rev() 使用:
gss_cat |>
mutate(marital = marital |> fct_infreq() |> fct_rev()) |>
ggplot(aes(x = marital)) +
geom_bar()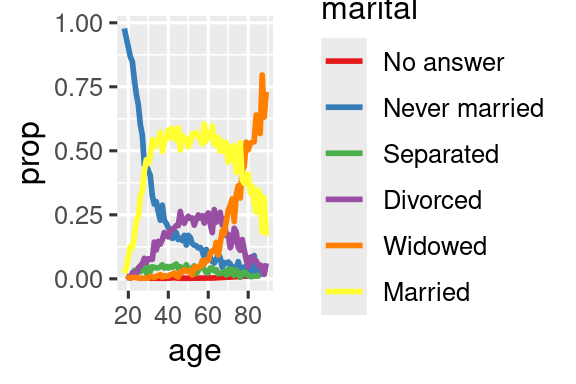
16.5 修改因子水平
除了修改顺序,还可修改水平名称。最通用的工具是 fct_recode()。
例如,下面针对 gss_cat 数据集中的 partyid(政党倾向)变量进行研究:
gss_cat |> count(partyid)
# A tibble: 10 × 2
partyid n
<fct> <int>
1 No answer 154
2 Don't know 1
3 Other party 393
4 Strong republican 2314
5 Not str republican 3032
6 Ind,near rep 1791
# ℹ 4 more rows可以看到这些水平名称长短不一。我们可以通过 fct_recode() 把它们改成更长、有固定格式的形式。和 tidyverse 中大多数重命名函数一样,新值写在左边,旧值写在右边:
gss_cat |>
mutate(
partyid = fct_recode(partyid,
"Republican, strong" = "Strong republican",
"Republican, weak" = "Not str republican",
"Independent, near rep" = "Ind,near rep",
"Independent, near dem" = "Ind,near dem",
"Democrat, weak" = "Not str democrat",
"Democrat, strong" = "Strong democrat"
)
) |>
count(partyid)输出:
# A tibble: 10 × 2
partyid n
<fct> <int>
1 No answer 154
2 Don't know 1
3 Other party 393
4 Republican, strong 2314
5 Republican, weak 3032
6 Independent, near rep 1791
# ℹ 4 more rows未被修改的水平会保持原样。如果误写了一个不存在的旧值,
fct_recode()会发出警告。
除了直接改名,也可以通过将多个旧值映射到同一个新值来合并类别。但是务必谨慎,如果合并了实际上差异较大的组别,很可能会造成误导:
gss_cat |>
mutate(
partyid = fct_recode(partyid,
"Republican, strong" = "Strong republican",
"Republican, weak" = "Not str republican",
"Independent, near rep" = "Ind,near rep",
"Independent, near dem" = "Ind,near dem",
"Democrat, weak" = "Not str democrat",
"Democrat, strong" = "Strong democrat",
"Other" = "No answer",
"Other" = "Don't know",
"Other" = "Other party"
)
)如果要合并若干组别到少数几个组别,fct_collapse() 比 fct_recode() 更清晰易读:
gss_cat |>
mutate(
partyid = fct_collapse(partyid,
"other" = c("No answer", "Don't know", "Other party"),
"rep" = c("Strong republican", "Not str republican"),
"ind" = c("Ind,near rep", "Independent", "Ind,near dem"),
"dem" = c("Not str democrat", "Strong democrat")
)
) |>
count(partyid)输出:
# A tibble: 4 × 2
partyid n
<fct> <int>
1 other 548
2 rep 5346
3 ind 8409
4 dem 7180有时想把一些频数特别少的类别合并为“Other”,以简化图表或表格。fct_lump_*() 系列函数专为此设计。
最简单粗暴的函数是fct_lump_lowfreq(),它会逐步合并频数最小的类别为 “Other”,并保证最终 “Other” 频数最小。
gss_cat |>
mutate(relig = fct_lump_lowfreq(relig)) |>
count(relig)输出:
# A tibble: 2 × 2
relig n
<fct> <int>
1 Protestant 10846
2 Other 10637能看出多数美国人是新教徒,但还想看到更多宗教的细分。那么此时要用到fct_lump_n()函数来限定分组数量,可以指定保留前 n 个最常见类别,其余合并为 “Other”:
gss_cat |>
mutate(relig = fct_lump_n(relig, n = 10)) |>
count(relig, sort = TRUE)输出示例:
# A tibble: 10 × 2
relig n
<fct> <int>
1 Protestant 10846
2 Catholic 5124
3 None 3523
4 Christian 689
5 Other 458
6 Jewish 388
# ℹ 4 more rows16.6 有序因子
下面简单介绍一种特殊类型的因子:有序因子。它是使用 ordered() 函数创建的,表示因子水平之间存在严格的顺序关系,但并不根据具体数值进行界定。
有序因子的顺序可以通过 < 符号进行识别:
ordered(c("a", "b", "c"))
#> [1] a b c
#> Levels: a < b < c