18 缺失值
18.1 引言
本书早些章节就已经出现过缺失值的基本概念。
显式缺失值即标记为 NA 的值,本章会从处理显式缺失值的一些通用工具讲起,随后介绍隐式缺失值,以及空因子组。
处理缺失值的函数主要来自于 dplyr 和 tidyr,都属于 tidyverse 包。
library(tidyverse)18.2 显式缺失值
本节介绍几个处理显式缺失值的工具,用于创建或消除NA。
在手动输入数据时,NA 往往用作一种简化手段,表示该单元格的值与上一行相同,即“向前填充”,称为 “last observation carried forward”,简称 locf。例如:
treatment <- tribble(
~person, ~treatment, ~response,
"Derrick Whitmore", 1, 7,
NA, 2, 10,
NA, 3, NA,
"Katherine Burke", 1, 4
)可以使用 tidyr::fill() 函数填补这些缺失值。该函数的参数类似 select(),用于指定要填充的列:
treatment |>
fill(everything())输出如下:
# A tibble: 4 × 3
person treatment response
<chr> <dbl> <dbl>
1 Derrick Whitmore 1 7
2 Derrick Whitmore 2 10
3 Derrick Whitmore 3 10
4 Katherine Burke 1 4若遇到更复杂的缺失模式,还可以通过 .direction 参数控制填充方向。
当缺失值代表一个固定且已知的值,比如 0时,可以使用 dplyr::coalesce() 来替换:
x <- c(1, 4, 5, 7, NA)
coalesce(x, 0)
#> [1] 1 4 5 7 0也可能遇到相反的情况:某个固定数值实际上代表缺失值。例如,某些旧软件无法用 NA 表示缺失,因此用特殊值如 99 或 -999 来代替。此时可使用 readr::read_csv() 的 na 参数在读取时即进行替换:
read_csv(path, na = "99")如果是在数据读取后才发现问题,或读取函数不支持该参数,可以使用 dplyr::na_if()在读取后进行替换:
x <- c(1, 4, 5, 7, -99)
na_if(x, -99)
#> [1] 1 4 5 7 NA在使用数学函数时,有时会遇到 NaN(Not a Number)。虽然它与 NA 类似,但语义上更偏向“数学上的无效结果”。
示例:
x <- c(NA, NaN)
x * 10
#> [1] NA NaN
x == 1
#> [1] NA NA
is.na(x)
#> [1] TRUE TRUE通常在如下数学运算中也会出现 NaN:
0 / 0 # 除以0未定义
#> [1] NaN
0 * Inf # 0 乘以无穷
#> [1] NaN
Inf - Inf # 无穷减无穷
#> [1] NaN
sqrt(-1) # 负数开平方
#> Warning in sqrt(-1): NaNs produced
#> [1] NaN虽然大多数情况下,NaN 与 NA 的行为类似,但在某些数值计算中区分它们可能是必要的。可使用 is.nan(x)进行区分:
x <- c(NA, NaN)
is.nan(x)
#> [1] FALSE TRUE18.3 隐式缺失值
有些时候,缺失的数据并不以 NA 的形式存在,而是整行数据根本就没出现在数据集中,称为隐式缺失值。
比如有一个数据集记录了某只股票每一季度的价格:
stocks <- tibble(
year = c(2020, 2020, 2020, 2020, 2021, 2021, 2021),
qtr = c( 1, 2, 3, 4, 2, 3, 4),
price = c(1.88, 0.59, 0.35, NA, 0.92, 0.17, 2.66)
)这个数据集中存在两个缺失情况:
- 2020 年第 4 季度的价格是缺失的,显示为
NA,为显式缺失。 - 2021 年第 1 季度的价格完全不在表里,这一行根本不存在,这就是隐式缺失。
作者用了一种“禅意”的表达方式来区分两者:
An explicit missing value is the presence of an absence.
An implicit missing value is the absence of a presence.
有时我们想把隐式缺失值变成显式的 NA,从而更方便地进行处理数据;而有时候,某些显式缺失值是由于数据结构不整洁造成的,我们又希望让它们隐式化,去掉无意义的 NA。下面介绍几个常用方法来实现这两种转换。
- 数据透视(pivoting)
之前已经学过,宽格式的数据(pivot_wider)会将隐式缺失变成显式 NA,因为每个组合都必须有对应值。比如我们把 qtr 这一列转成列名:
stocks |>
pivot_wider(
names_from = qtr,
values_from = price
)输出结果是:
# A tibble: 2 × 5
year `1` `2` `3` `4`
<dbl> <dbl> <dbl> <dbl> <dbl>
1 2020 1.88 0.59 0.35 NA
2 2021 NA 0.92 0.17 2.66可以看到原来缺失的一行(2021 年第 1 季度)现在以 NA 形式出现了。
反过来,从宽格式转回长格式(pivot_longer)时,会默认保留这些 NA。当然也可以选择用 values_drop_na = TRUE 参数把它们变成隐式。
- 使用
complete()明确地补全所有组合
tidyr::complete() 是一个强大函数,可以补全所有“本该存在”的组合,并用 NA 表示它们的缺失。
比如按理来说 year 和 qtr 所有组合都应该存在:
stocks |>
complete(year, qtr)输出:
# A tibble: 8 × 3
year qtr price
<dbl> <dbl> <dbl>
1 2020 1 1.88
2 2020 2 0.59
3 2020 3 0.35
4 2020 4 NA
5 2021 1 NA
6 2021 2 0.92
7 2021 3 0.17
8 2021 4 2.66甚至可以指定不在数据中的年份,比如要让数据从 2019 到 2021 则可以自动添加 2019 年所有季度的缺失行。
stocks |>
complete(year = 2019:2021, qtr)- 有时没法直接通过变量组合来生成完整数据。如果想手动控制哪些行应存在,则可以先创建完整的组合表,再用
full_join()合并。这样能获得跟complete()类似的效果,但更灵活:
full_frame <- expand_grid(
year = 2019:2021,
qtr = 1:4
)
stocks |>
full_join(full_frame)- 使用
anti_join()查找缺失记录
在某些情况下,只有通过对比两个数据集,才能发现哪些信息缺失了。这时可以用 anti_join()。
举个例子,要找出 flights 表中出现的机场代码 dest,但在 airports 数据表中没有信息的数据,就可以:
flights |>
distinct(faa = dest) |>
anti_join(airports)输出表明缺了 4 个机场信息。
18.4 因子和空组
缺失值还有一种不易察觉的形式:空组(empty group),指某个分组在数据中没有观测值,这种情况经常发生在使用因子时。
例如有一组健康调查数据:
health <- tibble(
name = c("Ikaia", "Oletta", "Leriah", "Dashay", "Tresaun"),
smoker = factor(c("no", "no", "no", "no", "no"), levels = c("yes", "no")),
age = c(34, 88, 75, 47, 56)
)这里的 smoker 是一个因子变量,其两个取值为 "yes" 和 "no"。现在要统计抽烟的人数:
health |> count(smoker)输出:
# A tibble: 1 × 2
smoker n
<fct> <int>
1 no 5默认情况下,只统计数据中实际出现的组,因此没有显示 "yes"。可以通过 .drop = FALSE 显式保留所有因子水平:
health |> count(smoker, .drop = FALSE)
# A tibble: 2 × 2
smoker n
<fct> <int>
1 yes 0
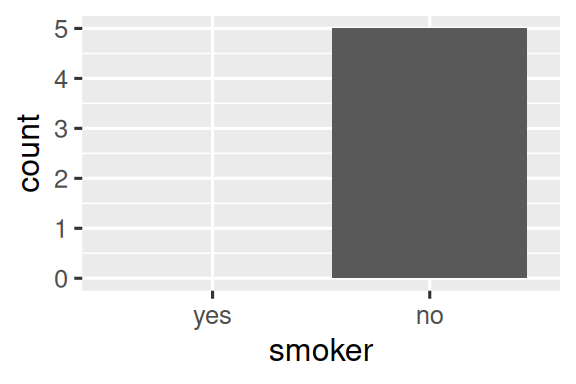
2 no 5用ggplot绘图时也会有此类问题。以柱状图为例:
ggplot(health, aes(x = smoker)) +
geom_bar()这时,图中只会有一个 "no" 的柱子,"yes" 组直接被省略了。
想要保留 "yes" 的空位置,只需:
ggplot(health, aes(x = smoker)) +
geom_bar() +
scale_x_discrete(drop = FALSE)这样,即使 "yes" 没有数据,也会显示在 x 轴上,柱子高度为 0。
不仅仅是绘图或计数,使用 group_by() 进行分组汇总时也默认丢弃空组,所以也需要.drop = FALSE参数进行补全:
health |>
group_by(smoker, .drop = FALSE) |>
summarize(
n = n(),
mean_age = mean(age),
min_age = min(age),
max_age = max(age),
sd_age = sd(age)
)
# A tibble: 2 × 6
smoker n mean_age min_age max_age sd_age
<fct> <int> <dbl> <dbl> <dbl> <dbl>
1 yes 0 NaN Inf -Inf NA
2 no 5 60 34 88 21.6因为yes组的相关数据处理是在空向量上进行计算,所以输出值各异。一一解释如下:
yes组是空的 →n = 0。- 计算平均值时是
0 / 0,结果是NaN。 min()返回Inf,max()返回-Inf。
另一种补全方式是先按实际数据汇总,再用 complete() 把空组加回来,这样得到的空组相关值是 NA :
health |>
group_by(smoker) |>
summarize(
n = n(),
mean_age = mean(age),
min_age = min(age),
max_age = max(age),
sd_age = sd(age)
) |>
complete(smoker)
# A tibble: 2 × 6
smoker n mean_age min_age max_age sd_age
<fct> <int> <dbl> <dbl> <dbl> <dbl>
1 yes NA NA NA NA NA
2 no 5 60 34 88 21.6