9 图层
9.1 引言
本章将在学习图形的分层语法时扩展ggplot2基础,从更深入地研究美学映射、几何对象和分面开始。然后介绍 ggplot2 在创建绘图时在后台进行的统计转换,这些变换用于计算要绘制的新值,例如条形图中条形的高度或箱形图中的中位数。另外还将了解位置调整,用于修改几何在绘图中的显示方式。最后,简要介绍坐标系相关内容。
9.2 美学映射
“The greatest value of a picture is when it forces us to notice what we never expected to see.” — John Tukey
mpg数据框与ggplot2包捆绑,包含 38 个汽车模型的 234 个观测值。
mpg
#> # A tibble: 234 × 11
#> manufacturer model displ year cyl trans drv cty hwy fl
#> <chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr>
#> 1 audi a4 1.8 1999 4 auto(l5) f 18 29 p
#> 2 audi a4 1.8 1999 4 manual(m5) f 21 29 p
#> 3 audi a4 2 2008 4 manual(m6) f 20 31 p
#> 4 audi a4 2 2008 4 auto(av) f 21 30 p
#> 5 audi a4 2.8 1999 6 auto(l5) f 16 26 p
#> 6 audi a4 2.8 1999 6 manual(m5) f 18 26 p
#> # ℹ 228 more rows
#> # ℹ 1 more variable: class <chr>变量解释:
displ:汽车的发动机尺寸,以升为单位。数值变量。hwy:汽车在高速公路上的燃油效率,以每加仑英里数 (mpg) 为单位。当它们行驶相同的距离时,燃油效率低的汽车比燃油效率高的汽车消耗更多的燃料。数值变量。class: 汽车类型。分类变量。
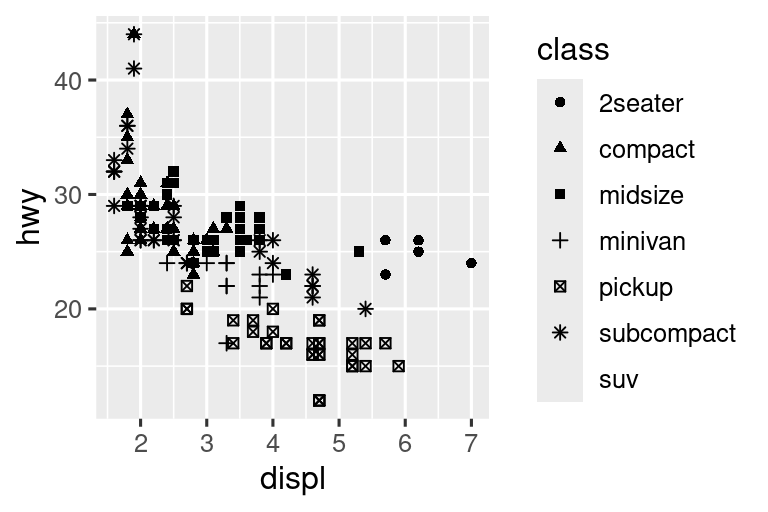
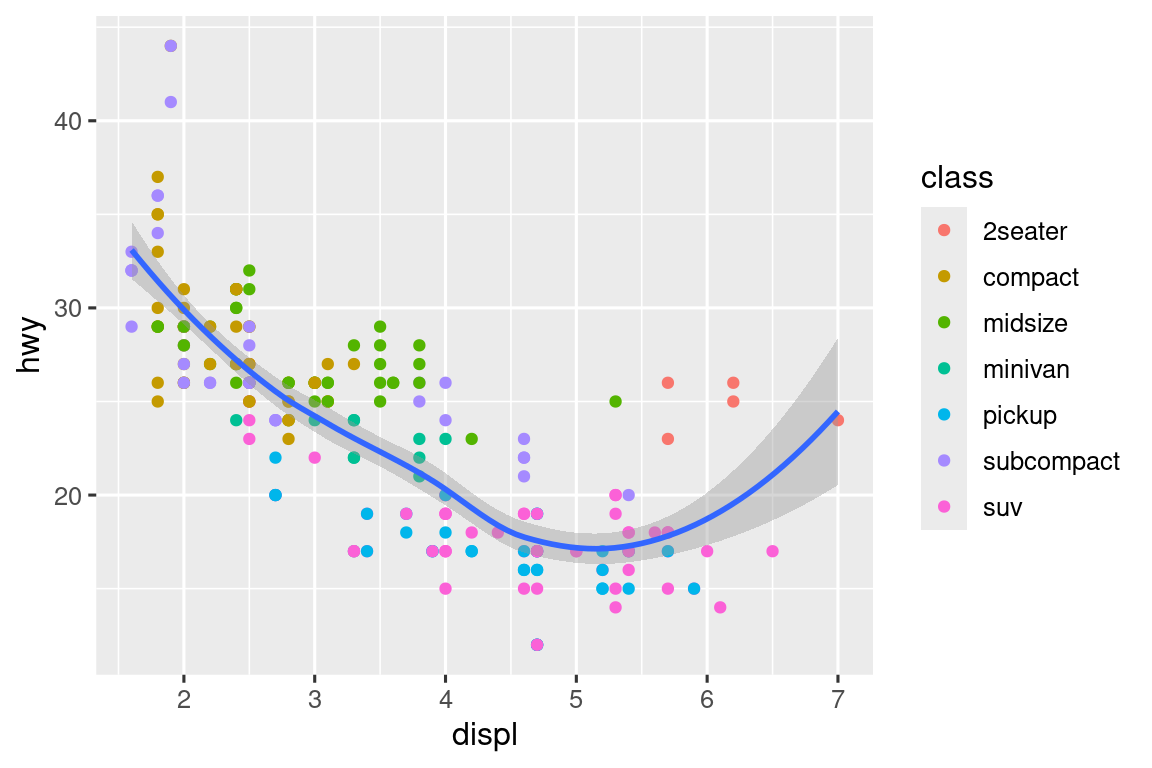
下面先初步可视化displ和hwy的关系。用散点图即可,数值变量映射到x和y美学,分类变量映射到color或shape美学。
# 上图
ggplot(mpg, aes(x = displ, y = hwy, color = class)) +
geom_point()
# 下图
ggplot(mpg, aes(x = displ, y = hwy, shape = class)) +
geom_point()
#> Warning: The shape palette can deal with a maximum of 6 discrete values because more
#> than 6 becomes difficult to discriminate
#> ℹ you have requested 7 values. Consider specifying shapes manually if you
#> need that many of them.
#> Warning: Removed 62 rows containing missing values or values outside the scale range
#> (`geom_point()`).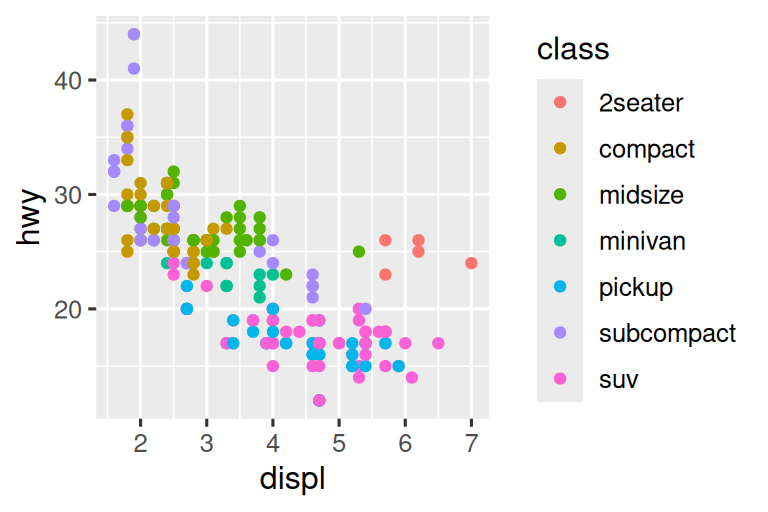
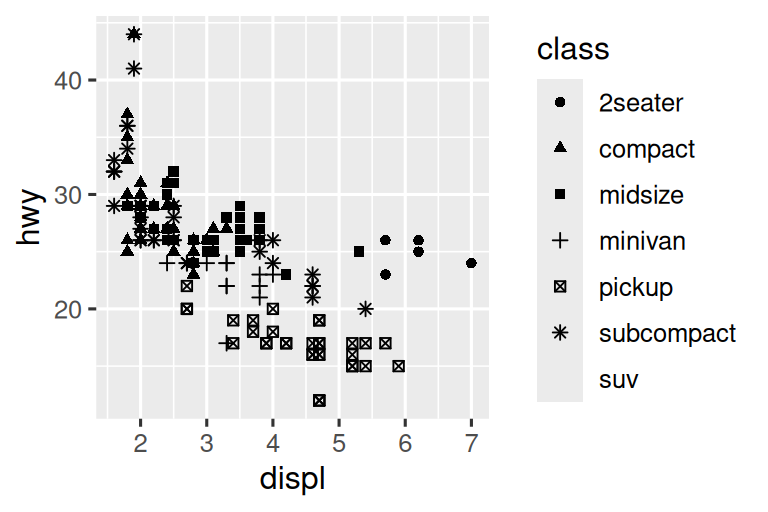
当映射到class和shape时,收到两个警告:
形状调色板最多可以处理 6 个离散值,因为超过 6 个就很难区分;现在有 7 个。如果必须具有形状,请考虑手动指定形状。
geom_point()删除了包含缺失值的 62 行。
同样,我们也可以将class映射到 size或alpha 美学,分别控制点的大小和透明度。
# 上图
ggplot(mpg, aes(x = displ, y = hwy, size = class)) +
geom_point()
#> Warning: Using size for a discrete variable is not advised.
# 下图
ggplot(mpg, aes(x = displ, y = hwy, alpha = class)) +
geom_point()
#> Warning: Using alpha for a discrete variable is not advised.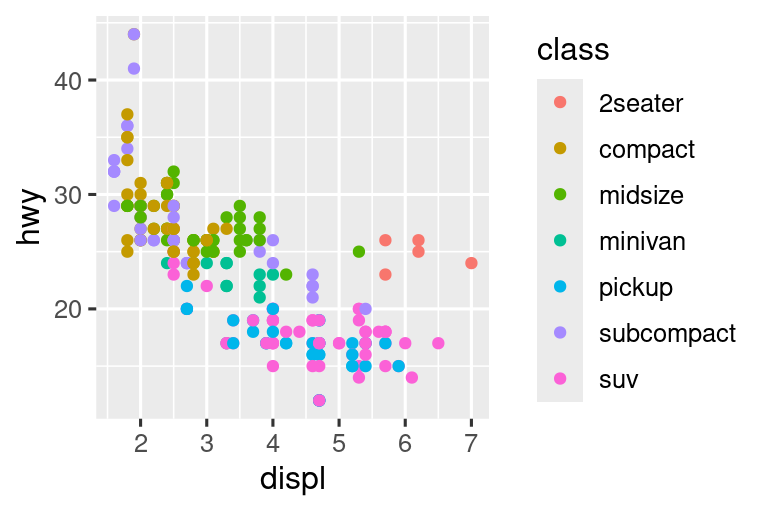
也会产生警告:
不建议对离散变量使用 alpha。
还可以手动将 geom 的视觉属性设置参数。例如,我们可以将绘图中的所有点设为蓝色:
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(color = "blue")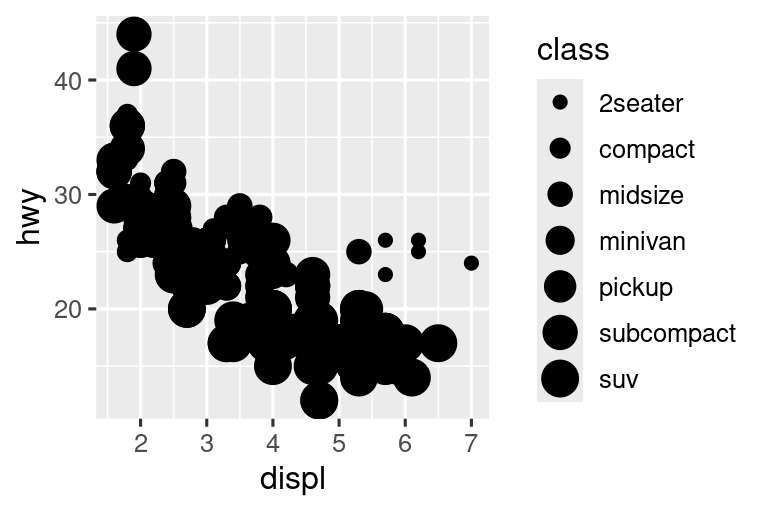
在这里,颜色不传达有关变量的信息,而只是更改绘图外观。
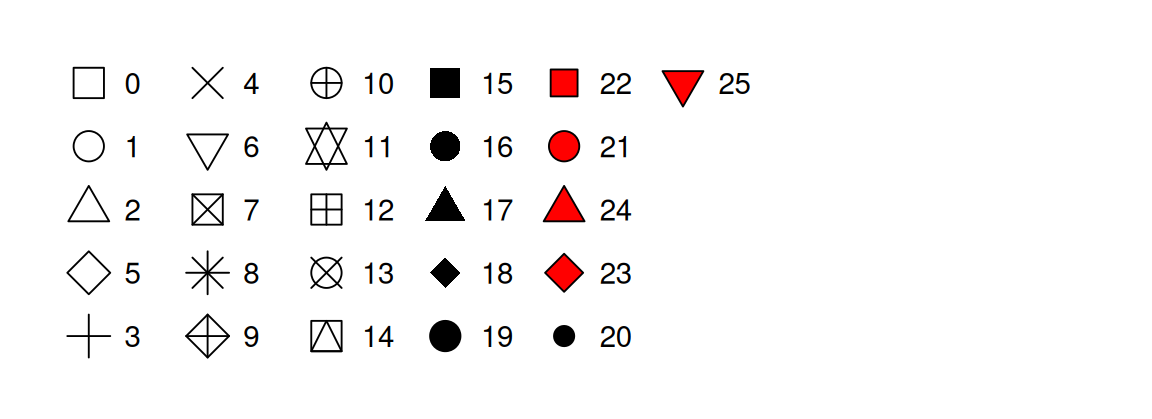
- 字符串形式的颜色名称,例如
color = "blue" - 以 mm 为单位的点的大小,例如
size = 1 - 点的形状以数字表示,例如
shape = 1。更多形状如图所示。
9.3 几何对象
9.3.1 相似点图分析
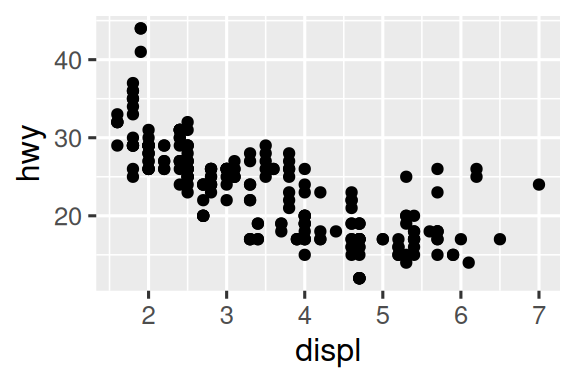
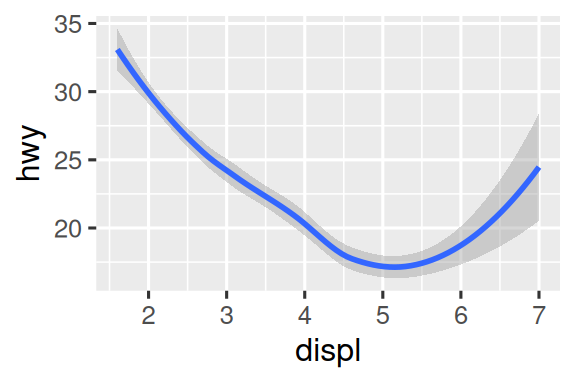
两幅图都展示了汽车高速燃油效率与发动机排量的关系。上边的图是散点图,下边的图显示了跟随这些变量关系轨迹的平滑曲线,并且周围还显示了置信区间。
虽然两幅图描述的是相同的数据,但它们并不完全相同。每幅图使用不同的几何对象(geom)来表示数据。左边的图使用点几何对象(point geom),右边的图使用平滑几何对象(smooth geom),即一条拟合数据的平滑线。
要改变图中的几何对象,可以更改ggplot()中的几何函数。例如,要分别创建上述两幅图,可以使用以下代码:
# 上图
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point()
# 下图
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_smooth()9.3.2 映射
ggplot2中的每个几何函数都接受一个映射参数,可以在几何层中局部定义,也可以在ggplot()层中全局定义。然而,并非每个美学属性都适用于每个几何对象。例如,可以设置点的形状,但不能设置所谓线的“type”。如果这样做,ggplot2会忽略该美学映射。
但是话又说回来,可以设置线的“linetype”。
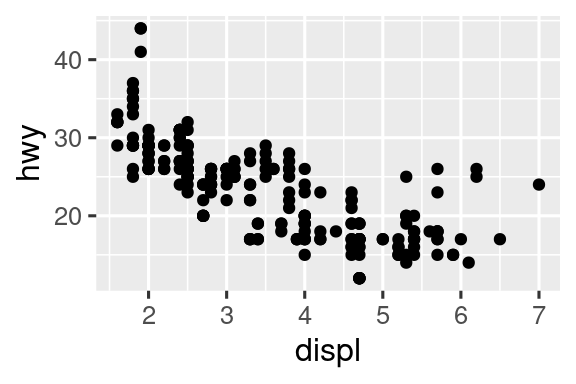
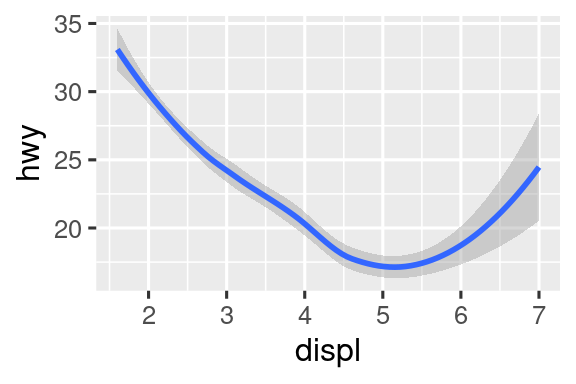
以下代码展示了如何使用不同的线型来表示不同类型驱动系统的汽车:
# 上图
ggplot(mpg, aes(x = displ, y = hwy, shape = drv)) +
geom_smooth()
# 下图
ggplot(mpg, aes(x = displ, y = hwy, linetype = drv)) +
geom_smooth()而且可以在同一图形中包含多个几何对象。例如,以下代码将原始数据点和平滑曲线叠加在一起:
ggplot(mpg, aes(x = displ, y = hwy, color = drv)) +
geom_point() +
geom_smooth(aes(linetype = drv))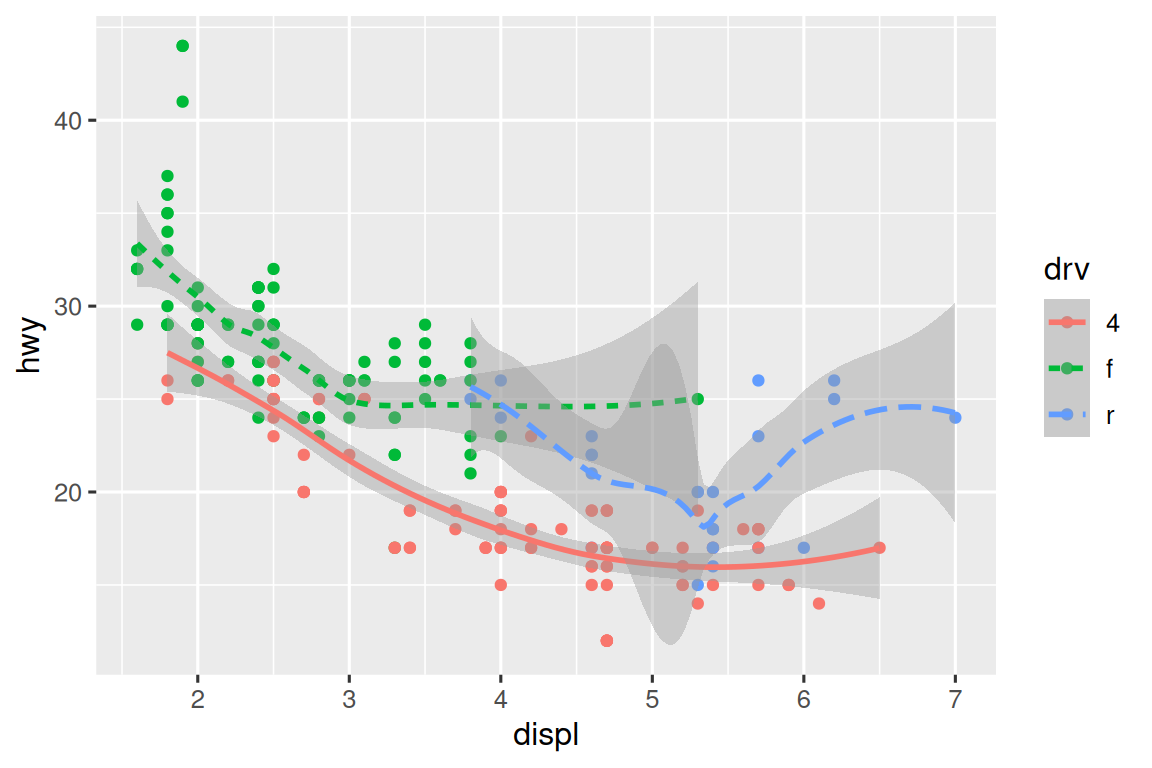
9.3.3 分组
许多几何函数,如geom_smooth(),使用单个几何对象来显示多行数据。对于这些函数,可以将其美学设置为分类变量来绘制多个对象。实践中,当将美学映射到离散变量时,ggplot2会自动为这些几何对象分组数据。
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_smooth(aes(color = drv), show.legend = FALSE)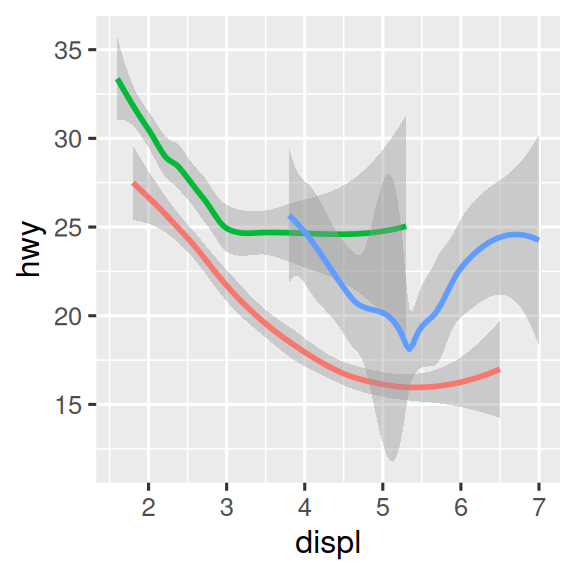
9.3.4 几何对象变换
几何对象是ggplot2的基本构建块。通过改变几何对象可改变图形的外观,从而揭示数据的不同特征。例如,下面的直方图和密度图揭示了高速里程的分布是双峰且右偏的,而箱线图则揭示了两个潜在的离群值。
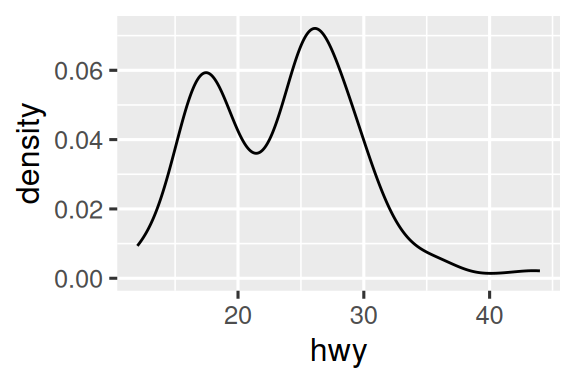
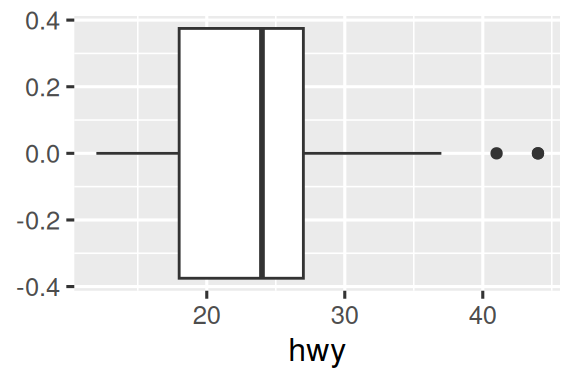
# 上图:直方图
ggplot(mpg, aes(x = hwy)) +
geom_histogram(binwidth = 2)
# 中图:密度图
ggplot(mpg, aes(x = hwy)) +
geom_density()
# 下图:箱线图
ggplot(mpg, aes(x = hwy)) +
geom_boxplot()9.3.5 扩展几何对象
ggplot2提供了40多种几何对象,但这些并不涵盖所有可能的图形。如果需要不同的几何对象,建议首先查看扩展包,看看是否有人已经实现了。例如,ggridges包可用于制作山脊线图,这对于可视化分类变量不同水平的数值变量的密度很有效。
library(ggridges)
ggplot(mpg, aes(x = hwy, y = drv, fill = drv, color = drv)) +
geom_density_ridges(alpha = 0.5, show.legend = FALSE)
9.4 分面
第一章介绍了使用facet_wrap()进行分面,它将图形分割为子图,每个子图基于一个分类变量显示数据的一个子集。
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point() +
facet_wrap(~cyl)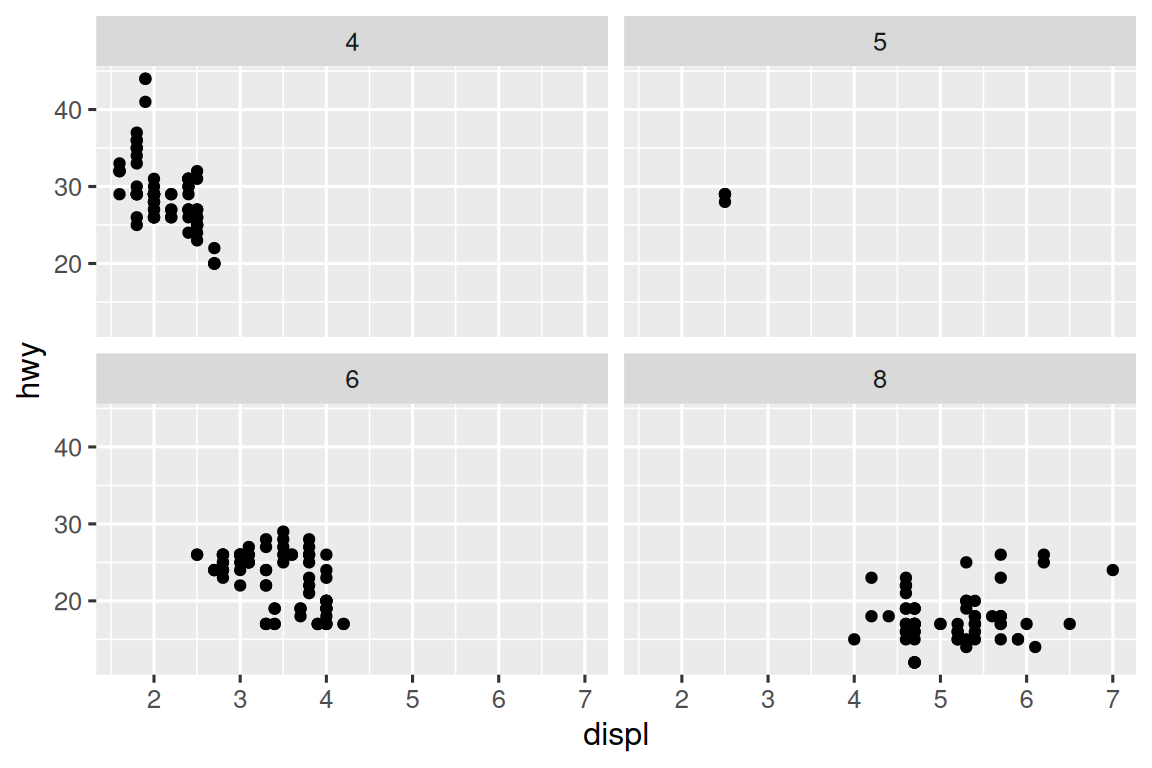
要用两个变量的组合对图形进行分面,可以从facet_wrap()切换到facet_grid()。facet_grid()的第一个参数形如行~列。
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point() +
facet_grid(drv ~ cyl)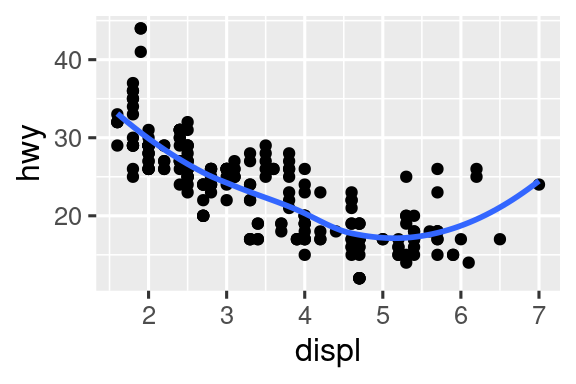
默认情况下,每个分面共享相同的x轴和y轴比例和范围。这在想要跨分面比较数据时很有效,但当想要更好地可视化每个分面内的关系时可能会受限制。在分面函数中设置scales参数为"free_x"可允许跨列的不同x轴比例,"free_y"可允许跨行的不同y轴比例,"free"则表示两者共存。
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point() +
facet_grid(drv ~ cyl, scales = "free")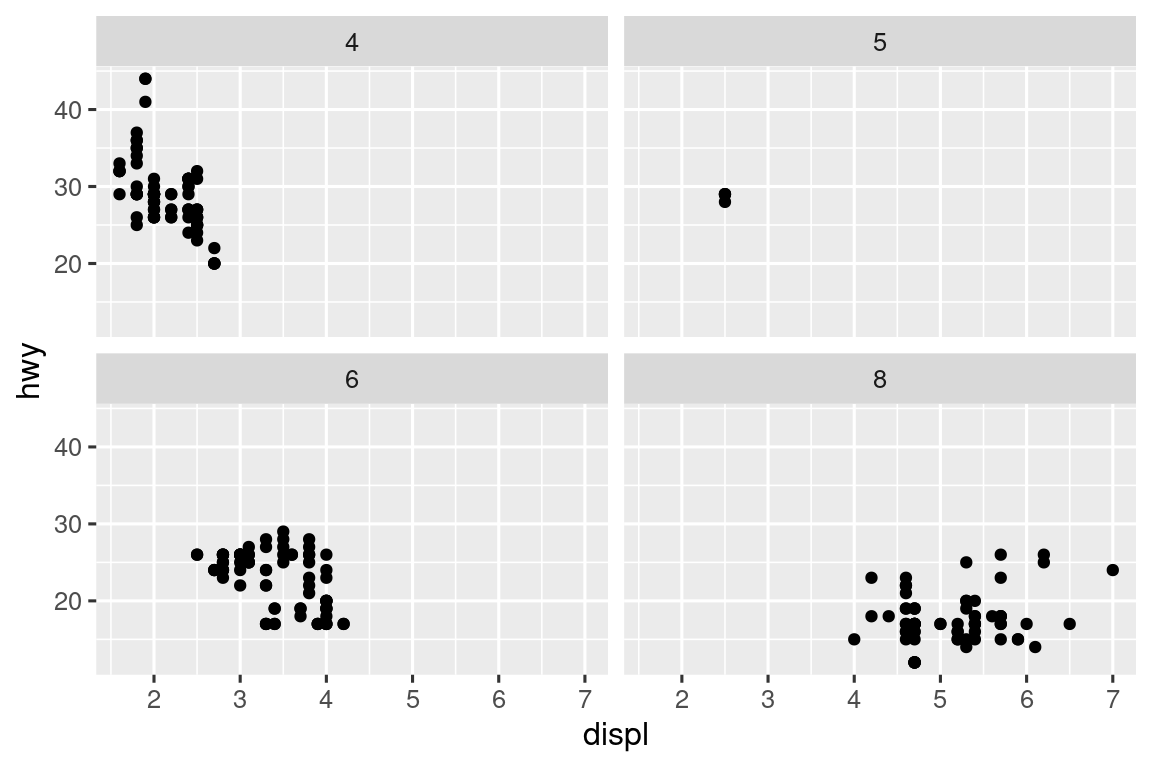
9.5 统计变换
以一个基础的柱状图为例,通过 geom_bar() 或 geom_col() 绘制。下图展示了 diamonds 数据集中按照切工(cut)分组的钻石总数。该数据集来自 ggplot2 包,包含约 5.4 万颗钻石的信息,包括每颗钻石的价格(price)、克拉数(carat)、颜色(color)、净度(clarity)和切工(cut)。图中显示,相较于低质量切工,拥有高质量切工的钻石更多。
ggplot(diamonds, aes(x = cut)) +
geom_bar()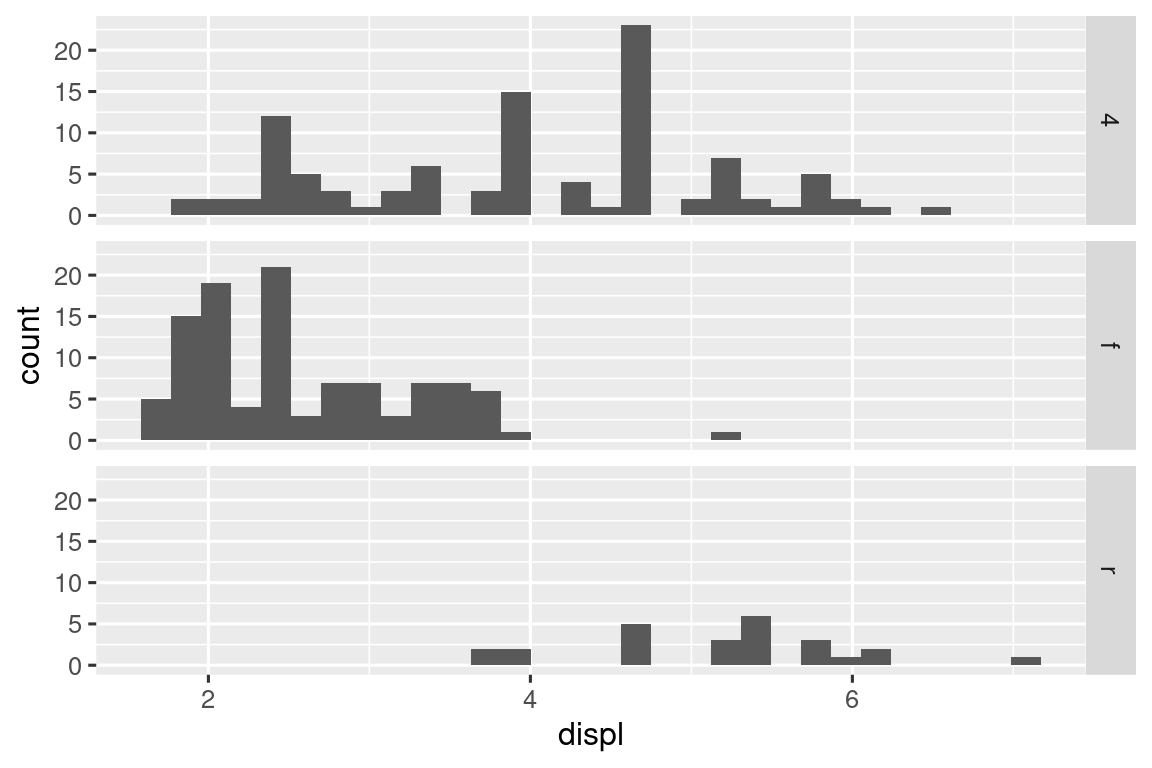
图的 x 轴是来自 diamonds 数据集的 cut 变量,而 y 轴显示的是 count,但 count 并不是 diamonds 中的变量!那么 count 是从哪里来的?
许多图形(如散点图)会绘制数据集中的原始值。而另一些图形(如柱状图)则会计算新的值进行绘图:
- 柱状图、直方图与频率多边图 会将数据分箱(bin),然后绘制每个箱中数据点的数量;
- 平滑曲线(smoothers) 会拟合模型并绘制模型预测值;
- 箱线图(boxplots) 会计算分布的五数摘要(最小值、下四分位数、中位数、上四分位数、最大值),并以特定格式的箱体呈现。
用于为图形计算新值的算法称为 stat,即统计变换(statistical transformation)的简称。下图展示了 geom_bar() 中这一过程的工作机制。
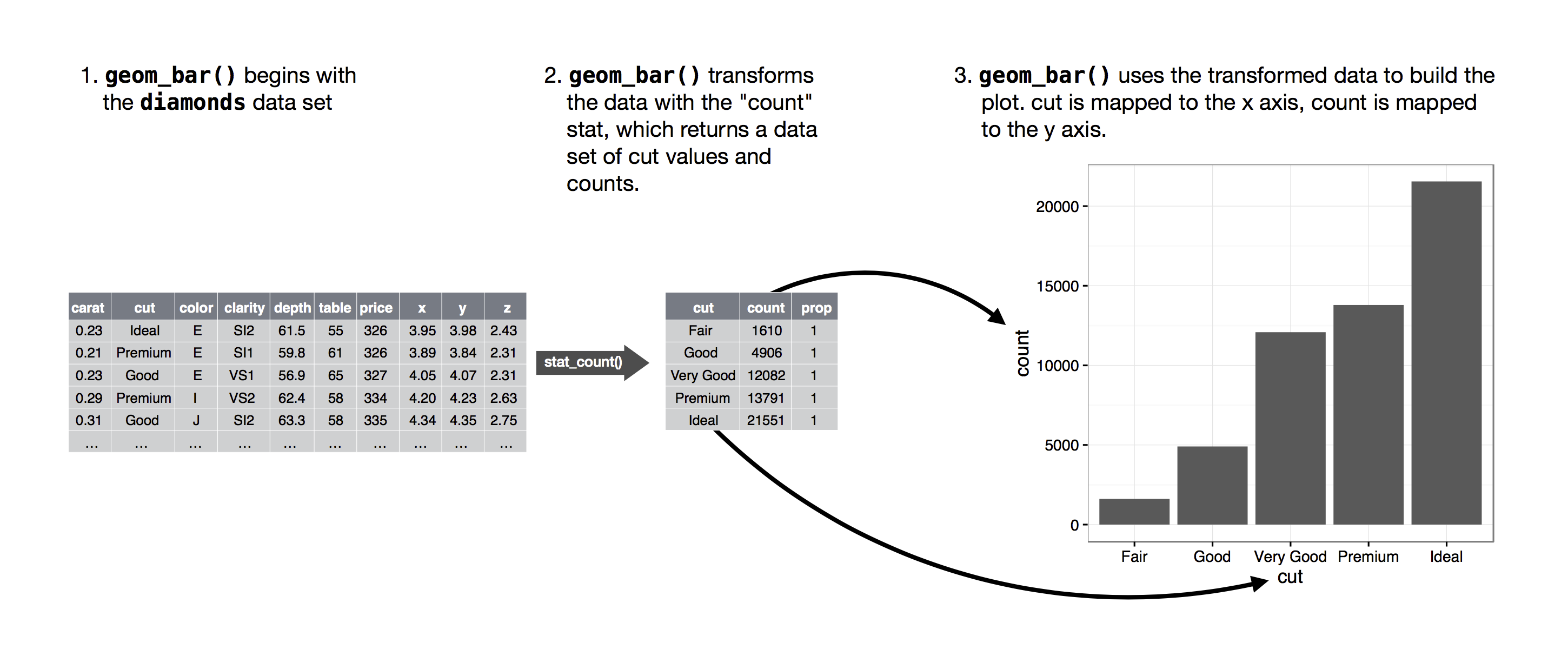
绘制柱状图的三个步骤: 第一步,
geom_bar()从原始数据集diamonds开始; 第二步,geom_bar()使用count这个 stat 对数据进行转换,生成一个包含 cut 值与 count 值的数据集; 第三步,geom_bar()使用这个经过变换的数据来构建图形:cut 映射到 x 轴,count 映射到 y 轴。简言之,当我们创建柱状图时,首先从原始数据出发,接着聚合以统计每个柱状的观测数,最后将这些计算所得的变量映射到图形属性上。
可以通过查看 stat 参数的默认值来了解某个 geom 使用了哪个 stat。例如,运行 ?geom_bar 可看到其默认的 stat 是 "count",这意味着 geom_bar() 实际上使用的是 stat_count()。stat_count() 的文档与 geom_bar() 在同一页面上。如果向下滚动,可以在“Computed variables”(计算变量)部分看到该 stat 计算出两个新变量:count 与 prop。
每个 geom 都有一个默认的 stat,每个 stat 也有一个默认的 geom。因此,通常在使用 geoms 时无需考虑背后的统计变换。但在以下三种情形下,可能需要显式使用 stat:
- 重设默认的 stat
在下面的代码中,将 geom_bar() 的 stat 从默认的 "count" 更改为 "identity"。这样可以将柱子的高度直接映射为某个变量的原始值,而非自动统计得到的数量。
diamonds |>
count(cut) |>
ggplot(aes(x = cut, y = n)) +
geom_bar(stat = "identity")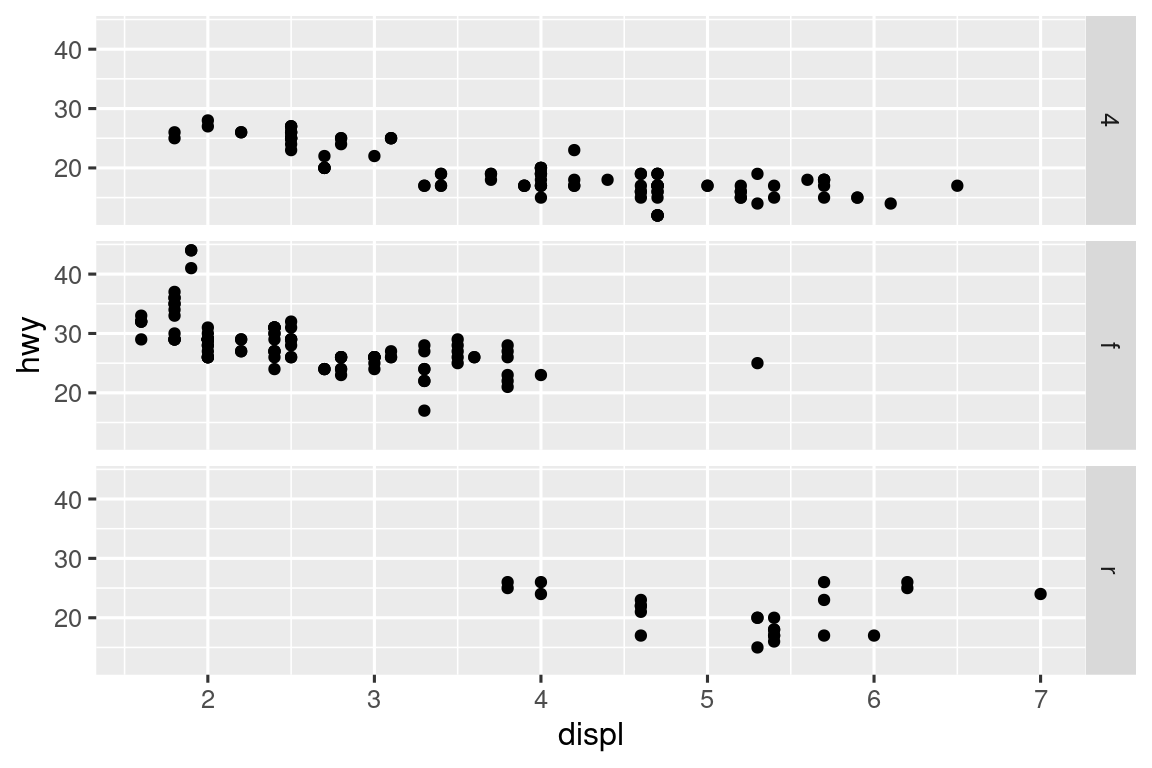
- 重写变换后变量的美学映射
例如,可能希望绘制柱状图显示每类钻石的比例,而不是数量:
ggplot(diamonds, aes(x = cut, y = after_stat(prop), group = 1)) +
geom_bar()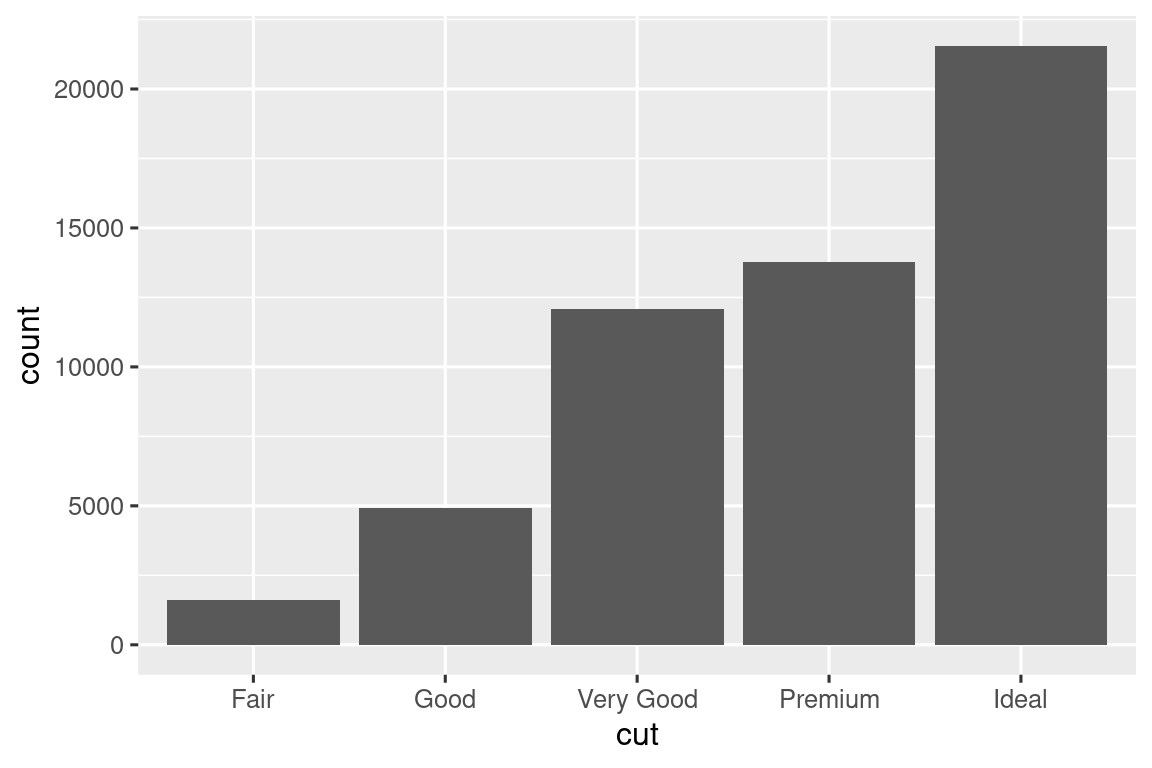
- 在代码中明确突出统计变换的过程
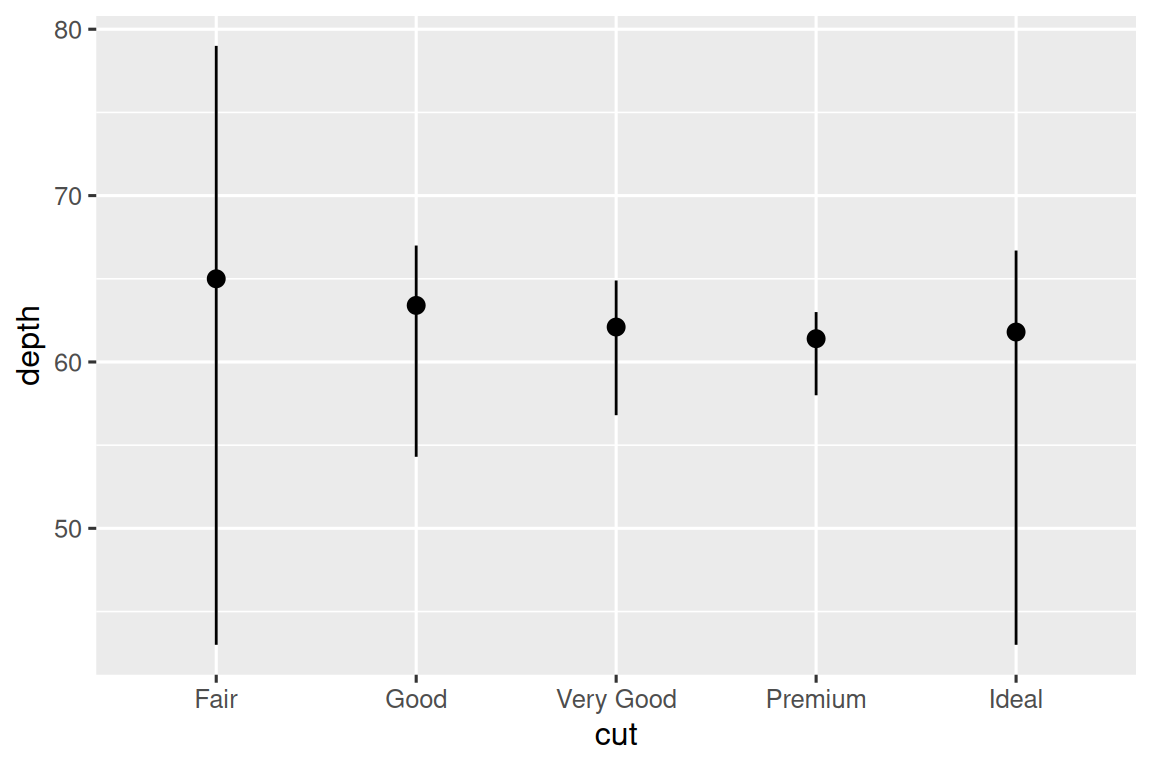
例如,可以使用 stat_summary() 来强调正在对 y 值进行摘要计算:该 stat 会对每个唯一的 x 值进行汇总。
ggplot(diamonds) +
stat_summary(
aes(x = cut, y = depth),
fun.min = min,
fun.max = max,
fun = median
)
ggplot2 提供了超过 20 种 stat 可供使用。每一个 stat 都是一个函数,因此可以通过 ?stat_bin 的形式获取帮助文档。
9.6 位置调整
条形图可通过颜色美学(color)或填充美学(fill)着色。例如:
# 上图
ggplot(mpg, aes(x = drv, color = drv)) +
geom_bar()
# 下图
ggplot(mpg, aes(x = drv, fill = drv)) +
geom_bar()
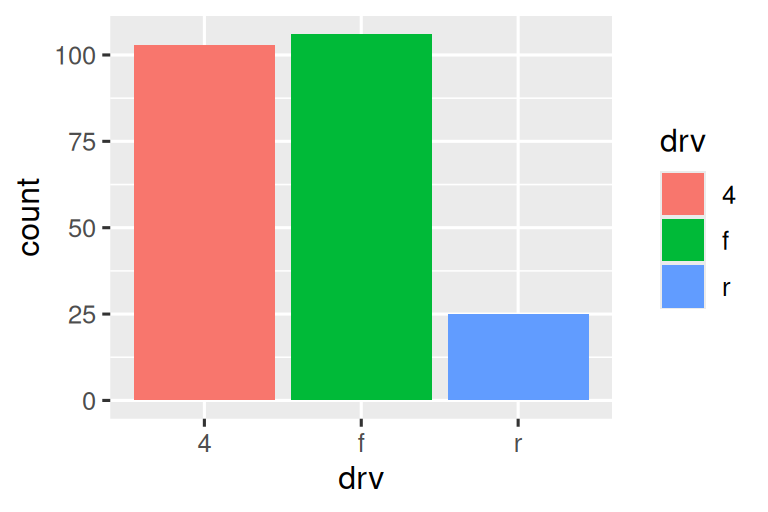
上图的条形仅显示彩色边框,下图的条形则填充了颜色。条形高度对应每种驱动类型(drv)的汽车数量。
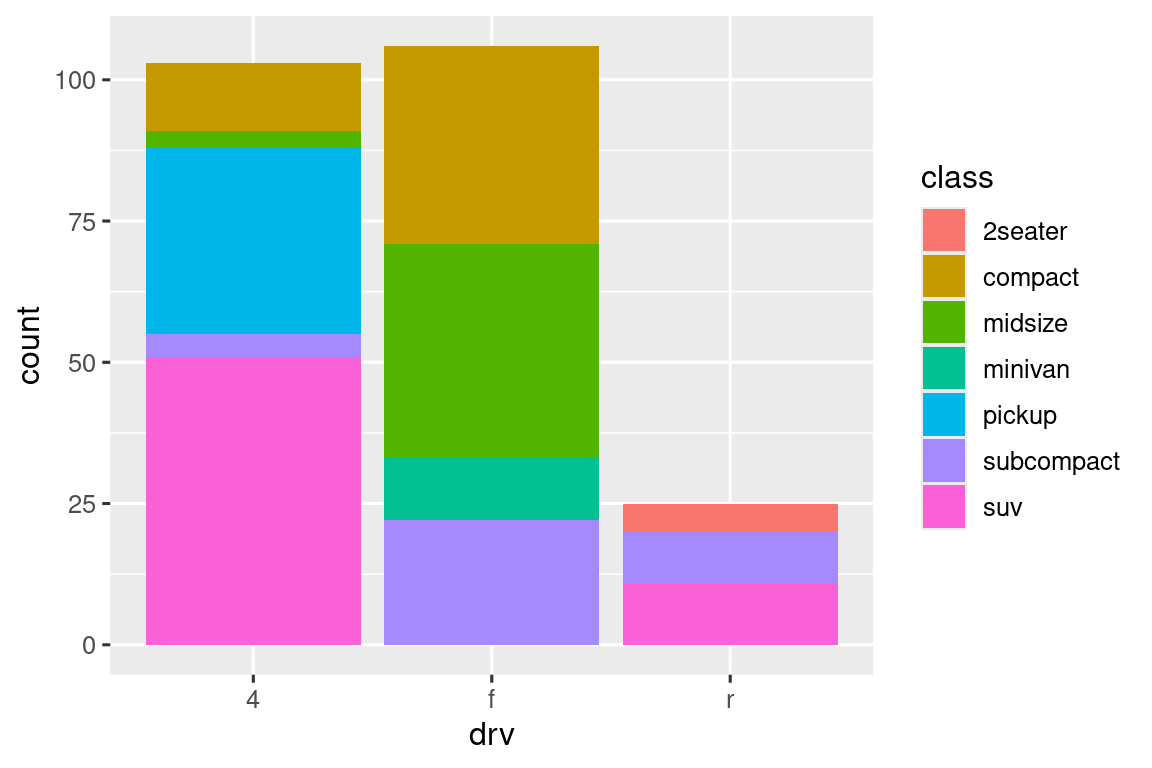
如果将填充美学映射到另一个变量(如 class),条形会自动堆叠:
ggplot(mpg, aes(x = drv, fill = class)) +
geom_bar()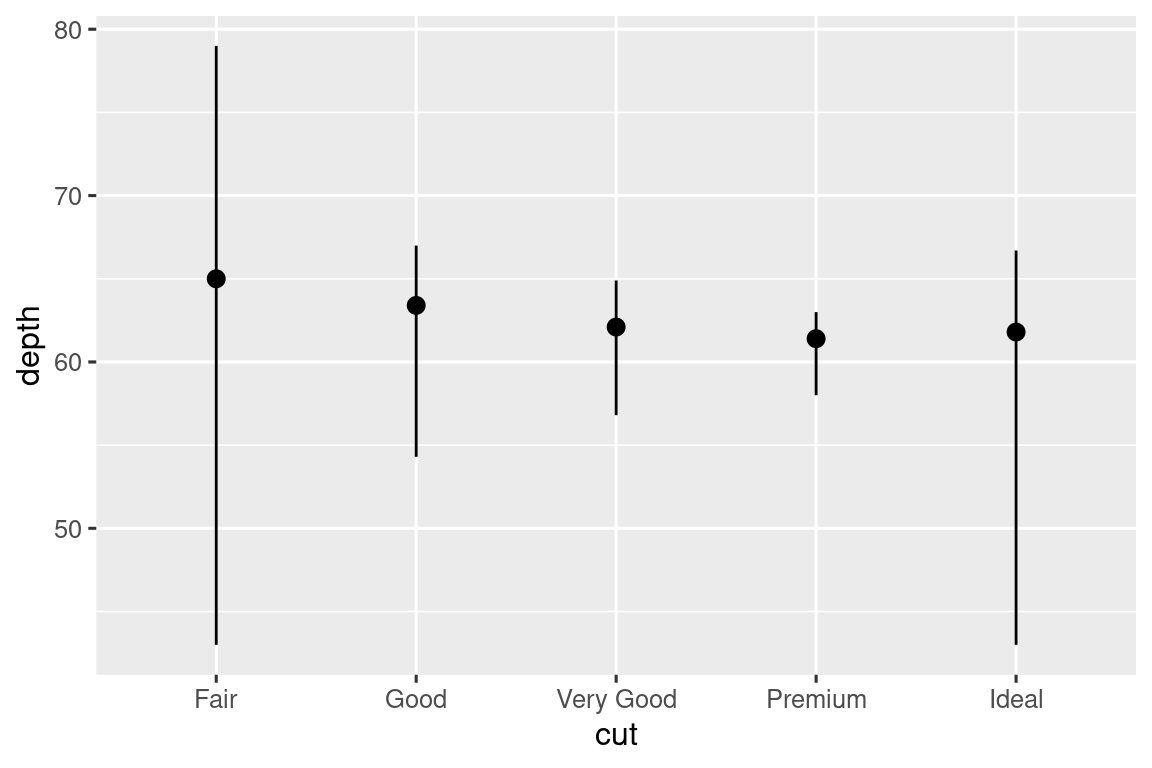
堆叠条形图显示汽车驱动类型,每个条形按汽车类别(class)填充颜色。条形总高度表示驱动类型的车辆总数,各色块高度表示该驱动类型下不同类别的车辆数量。
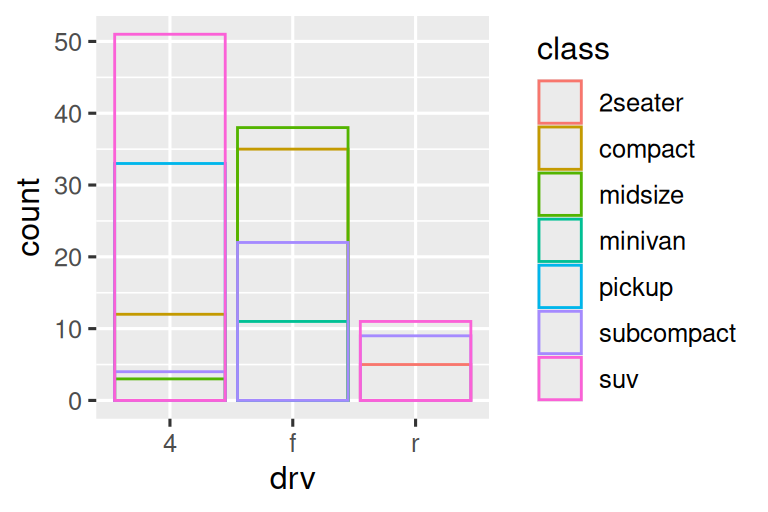
堆叠效果由 position 参数自动控制。若需取消堆叠,有三种方式:
position = "identity"将每个对象精确绘制在其原始位置(条形会重叠,需配合透明度使用):
# 上图:半透明填充 ggplot(mpg, aes(x = drv, fill = class)) + geom_bar(alpha = 1/5, position = "identity") # 下图:无填充仅边框 ggplot(mpg, aes(x = drv, color = class)) + geom_bar(fill = NA, position = "identity")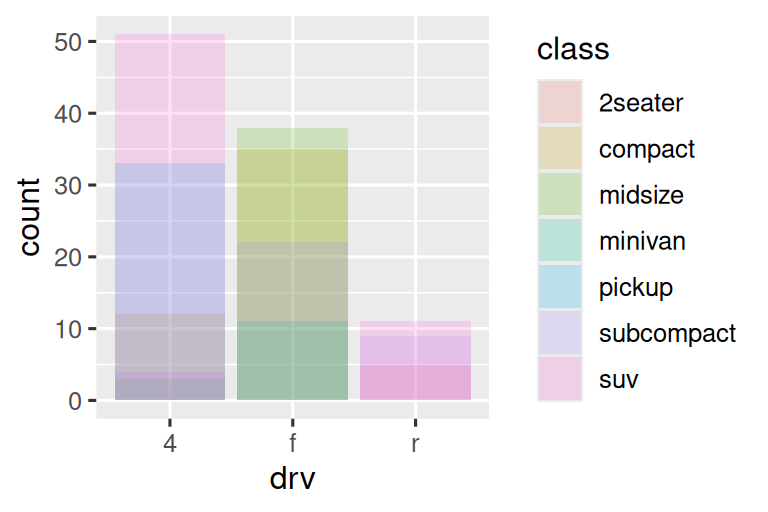
position = "fill"堆叠并标准化高度为1,各色块高度表示类别在驱动类型中的占比:
ggplot(mpg, aes(x = drv, fill = class)) + geom_bar(position = "fill")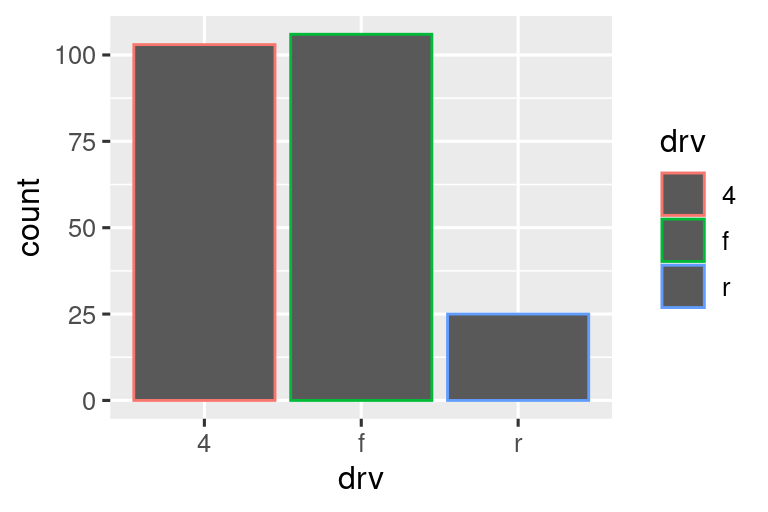
position = "dodge"并列排列重叠对象,便于直接比较数值:
ggplot(mpg, aes(x = drv, fill = class)) + geom_bar(position = "dodge")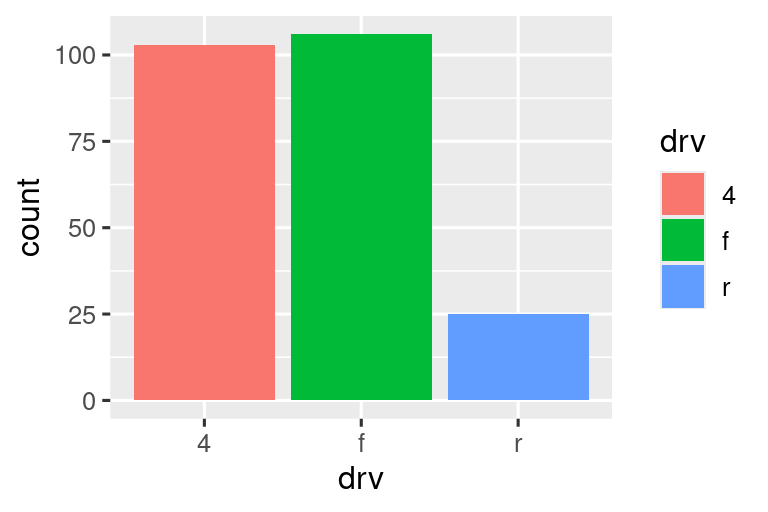
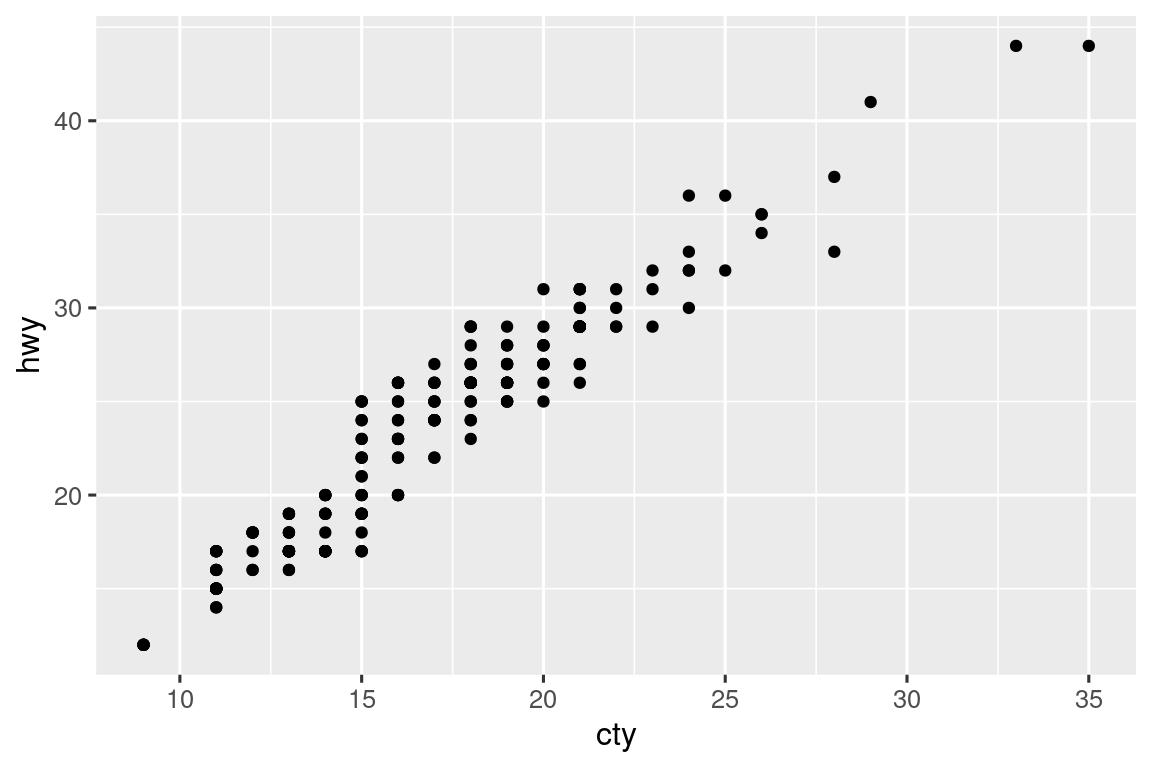
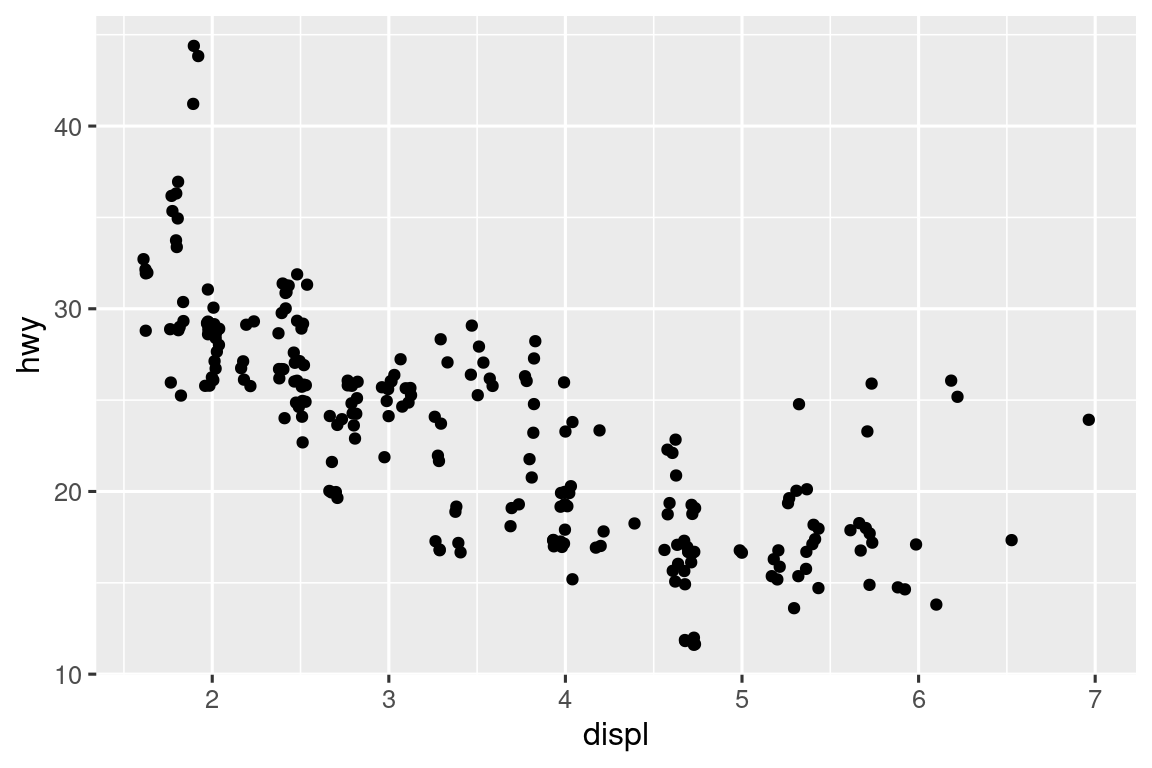
有时散点图存在过度绘制问题,如下图中数据取整导致点重叠。
通过 position = "jitter" 添加轻微随机扰动可缓解:
ggplot(mpg, aes(x = displ, y = hwy)) +
geom_point(position = "jitter")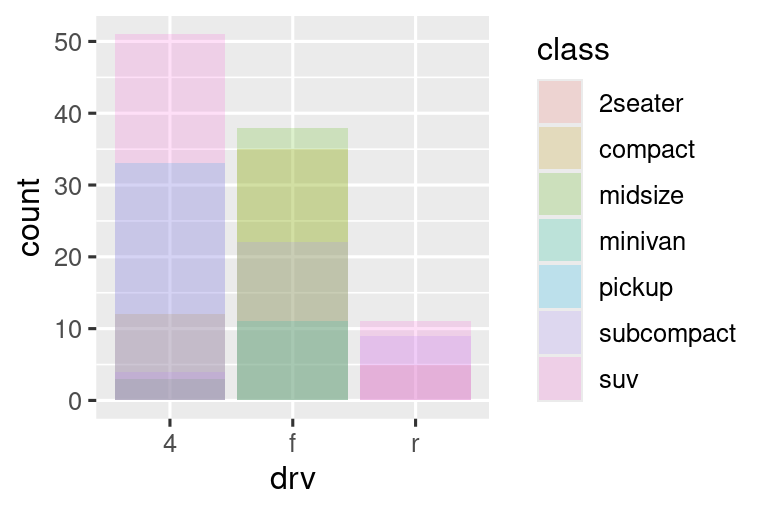
抖动散点图显示发动机排量(displ)与高速油耗(hwy)的负相关。虽然小尺度精度下降,但大尺度分布更清晰。另有快捷函数 geom_jitter() 等效于 geom_point(position = "jitter")。
9.7 坐标系系统
ggplot2 默认使用笛卡尔坐标系(Cartesian),x 和 y 轴独立定位点位置。此外还有两种特殊坐标系:
- 地理地图矫正:
coord_quickmap()
绘制地理空间数据时,可通过此函数校正长宽比例(保持地图不变形)。以下以新西兰地图为例:
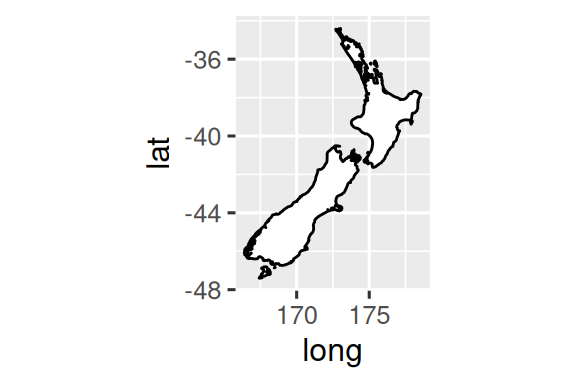
nz <- map_data("nz")
# 未校正比例(上图)
ggplot(nz, aes(x = long, y = lat, group = group)) +
geom_polygon(fill = "white", color = "black")
# 校正比例(下图)
ggplot(nz, aes(x = long, y = lat, group = group)) +
geom_polygon(fill = "white", color = "black") +
coord_quickmap()两图对比新西兰边界:左图比例失真,右图通过 coord_quickmap() 保持正确地理比例。
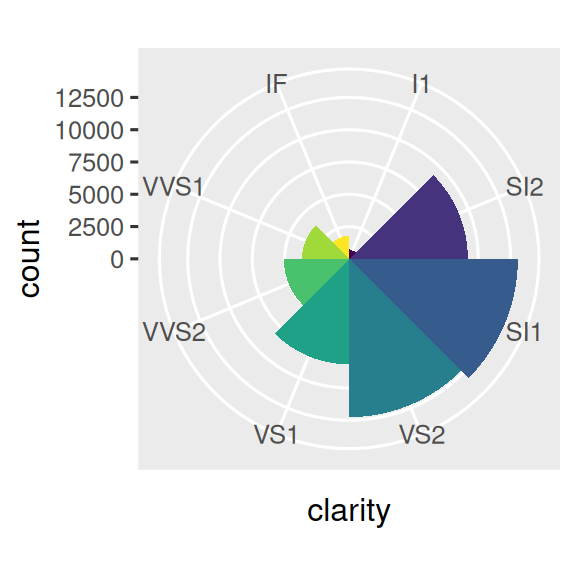
- 极坐标系:
coord_polar()
将条形图转换为玫瑰图(Coxcomb chart),可揭示数据分布的周期性,每个类别对应一个扇形区域。
# 基础条形图(长宽比设为1:1)
bar <- ggplot(diamonds) +
geom_bar(
aes(x = clarity, fill = clarity),
show.legend = FALSE,
width = 1
) +
theme(aspect.ratio = 1)
# 横向条形图(上图)
bar + coord_flip()
# 极坐标转换的玫瑰图(下图)
bar + coord_polar()